ไขปริศนา Vector Embeddings และ Vector Databases: กุญแจสู่โลกข้อมูลอัจฉริยะ
ในโลกยุคดิจิทัลที่ข้อมูลหลั่งไหลไม่หยุด การทำความเข้าใจและจัดการข้อมูลจำนวนมหาศาลกลายเป็นเรื่องท้าทายอย่างยิ่ง Vector Embeddings และ Vector Databases คือสองหัวใจสำคัญที่เข้ามาช่วยปลดล็อกศักยภาพของข้อมูล ทำให้สามารถทำงานกับข้อมูลเชิงความหมายได้อย่างชาญฉลาดมากยิ่งขึ้น บทความนี้จะพาไปทำความรู้จักกับนวัตกรรมเหล่านี้อย่างเจาะลึกและเข้าใจง่าย
ทำความเข้าใจ Vector Embeddings
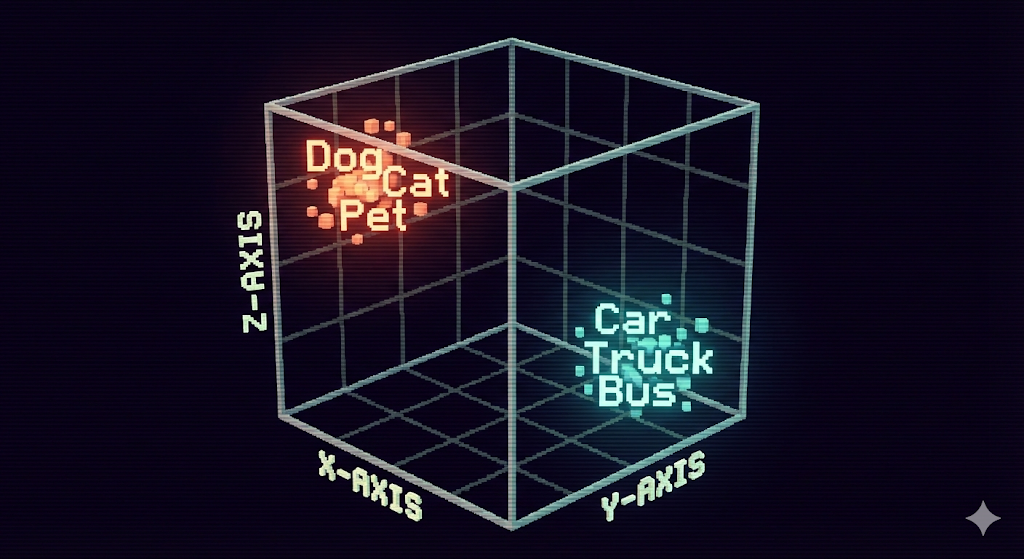
ลองนึกภาพว่าเราต้องการให้คอมพิวเตอร์เข้าใจสิ่งต่างๆ เช่น ข้อความ รูปภาพ หรือแม้กระทั่งเสียง Vector Embeddings คือกระบวนการแปลงข้อมูลเหล่านี้ให้กลายเป็นชุดตัวเลข หรือที่เรียกว่า เวกเตอร์ ในมิติที่หลากหลาย คล้ายกับการสร้างแผนที่พิกัดทางคณิตศาสตร์สำหรับข้อมูลแต่ละชิ้น
ความมหัศจรรย์ของ Vector Embeddings คือการที่เวกเตอร์เหล่านี้สามารถเก็บ ความหมายเชิงบริบท ของข้อมูลไว้ได้ ข้อมูลที่มีความหมายใกล้เคียงกัน จะมีเวกเตอร์ที่อยู่ใกล้กันในพื้นที่มิตินั้นๆ ทำให้ระบบสามารถเข้าใจความสัมพันธ์และความคล้ายคลึงกันระหว่างข้อมูลได้อย่างแม่นยำ ยกตัวอย่างเช่น คำว่า ‘แอปเปิล’ ที่หมายถึงผลไม้ กับ ‘แอปเปิล’ ที่หมายถึงบริษัทเทคโนโลยี แม้จะเป็นคำเดียวกัน แต่เวกเตอร์ที่ถูกสร้างขึ้นจะแตกต่างกันอย่างชัดเจนตามบริบท
Vector Databases คืออะไร?
เมื่อมี Vector Embeddings จำนวนมหาศาล การจัดเก็บและการค้นหาข้อมูลที่มีประสิทธิภาพก็เป็นสิ่งจำเป็น นี่คือบทบาทของ Vector Databases ซึ่งเป็นฐานข้อมูลที่ออกแบบมาโดยเฉพาะเพื่อจัดการกับเวกเตอร์เหล่านี้ ต่างจากฐานข้อมูลแบบดั้งเดิมที่เน้นการค้นหาแบบตรงตัวหรือใช้โครงสร้างข้อมูลที่ตายตัว
Vector Databases เก่งกาจในการทำ การค้นหาความคล้ายคลึง (Similarity Search) นั่นคือการหาข้อมูลที่มีเวกเตอร์ใกล้เคียงกับเวกเตอร์ที่เรากำลังค้นหา โดยใช้เทคนิคขั้นสูงอย่าง ANN (Approximate Nearest Neighbor) เพื่อค้นหาเวกเตอร์ที่คล้ายกันได้อย่างรวดเร็วแม้ในชุดข้อมูลขนาดใหญ่ ทำให้สามารถตอบคำถามเชิงความหมายที่ซับซ้อนได้
ประโยชน์และการนำไปใช้งานจริง
ศักยภาพของ Vector Embeddings และ Vector Databases นั้นกว้างไกลอย่างไม่น่าเชื่อ การนำไปใช้งานที่เห็นได้ชัดเจนคือ การค้นหาเชิงความหมาย (Semantic Search) ที่ช่วยให้การค้นหาไม่ได้จำกัดแค่คำสำคัญ แต่เป็นการค้นหาตามเจตนาและความหมาย เช่น การค้นหา ‘รองเท้าที่ใส่สบาย’ อาจพบผลลัพธ์เป็น ‘รองเท้าผ้าใบ’ นอกจากนี้ยังถูกใช้ใน ระบบแนะนำสินค้า/บริการ เพื่อแนะนำสิ่งที่คล้ายคลึงกับสิ่งที่ผู้ใช้เคยสนใจ และ การตรวจจับความผิดปกติ (Anomaly Detection) เพื่อระบุข้อมูลที่แตกต่างจากกลุ่ม
ในยุคของ Generative AI และ โมเดลภาษาขนาดใหญ่ (LLMs) เทคโนโลยีนี้ยิ่งทวีความสำคัญ Vector Databases เป็นหัวใจสำคัญของเทคนิค RAG (Retrieval-Augmented Generation) ซึ่งช่วยให้ LLMs สามารถดึงข้อมูลที่เกี่ยวข้องและเป็นปัจจุบันจากแหล่งข้อมูลภายนอกมาใช้ในการสร้างคำตอบ ทำให้ได้ข้อมูลที่ถูกต้องแม่นยำ ลดการสร้างข้อมูลที่ผิดพลาด (hallucinations) และเพิ่มความน่าเชื่อถือของการตอบกลับ
โลกแห่งข้อมูลกำลังเปลี่ยนแปลงไปอย่างรวดเร็ว และการทำความเข้าใจในแก่นแท้ของ Vector Embeddings และ Vector Databases จะช่วยให้เราสามารถสร้างสรรค์นวัตกรรมใหม่ๆ พัฒนาระบบอัจฉริยะที่ชาญฉลาด และนำข้อมูลมาใช้ให้เกิดประโยชน์สูงสุดในทุกมิติของการดำเนินชีวิตประจำวันและธุรกิจในอนาคต