จุดเปลี่ยนแห่ง AI: เมื่อโลกได้รู้จักกับ Transformer และพลังของมัน
วงการปัญญาประดิษฐ์ในปัจจุบันก้าวหน้าไปไกลอย่างก้าวกระโดด เห็นได้จากความสามารถของโมเดลภาษาขนาดใหญ่ที่สามารถเข้าใจและสร้างข้อความได้อย่างน่าทึ่ง ทว่า เบื้องหลังความสำเร็จเหล่านี้ มีเทคโนโลยีพื้นฐานสำคัญที่เปรียบเสมือนหัวใจขับเคลื่อน และนั่นคือสถาปัตยกรรม Transformer ที่ถือกำเนิดขึ้นในปี 2017
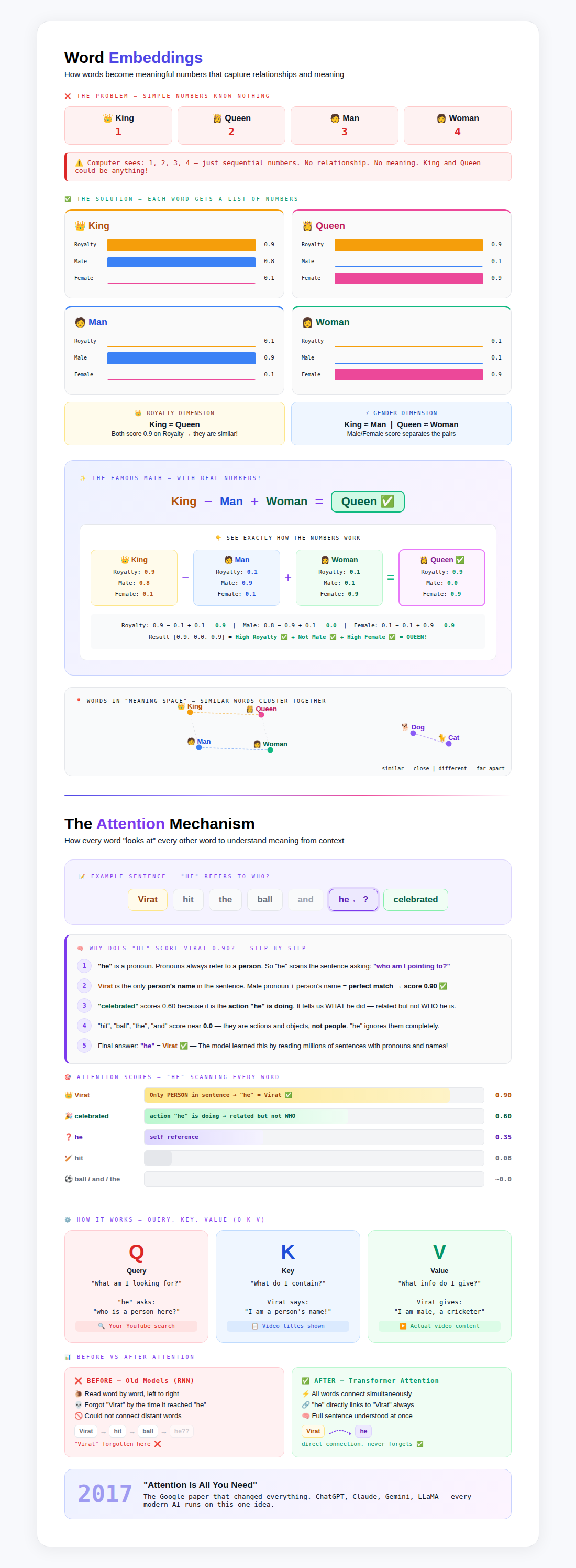
ก่อนจะเจาะลึกถึงความยิ่งใหญ่ของ Transformer การทำความเข้าใจแนวคิดเรื่อง Embeddings ถือเป็นสิ่งสำคัญอย่างยิ่ง Embeddings คือการแปลงคำศัพท์หรือข้อมูลใดๆ ให้กลายเป็นเวกเตอร์ตัวเลขในมิติสูง พูดง่ายๆ คือเปลี่ยนคำที่คนเข้าใจให้เป็นภาษาที่คอมพิวเตอร์ประมวลผลได้ โดยที่คำที่มีความหมายใกล้เคียงกันจะมีเวกเตอร์ที่อยู่ใกล้กันในพื้นที่นั้นๆ ทำให้ AI สามารถ “เข้าใจ” ความสัมพันธ์เชิงความหมายของคำต่างๆ ได้
ปัญหาโลกแตกก่อน Transformer จะเข้ามา
ก่อนปี 2017 โมเดล AI ที่ใช้ประมวลผลภาษาธรรมชาติส่วนใหญ่พึ่งพาสถาปัตยกรรมแบบ Recurrent Neural Networks (RNNs) หรือ Long Short-Term Memory (LSTMs) ซึ่งทำงานแบบลำดับขั้น หรือ sequential processing
หมายความว่าโมเดลจะประมวลผลคำทีละคำตามลำดับในประโยค วิธีนี้มีข้อจำกัดอย่างมากเมื่อต้องจัดการกับประโยคที่ยาวมากๆ ทำให้โมเดลลืมข้อมูลสำคัญที่อยู่ต้นประโยคไปเสียก่อนที่จะไปถึงปลายประโยค หรือที่เรียกว่าปัญหา long-term dependencies
นอกจากนี้ การประมวลผลแบบลำดับยังทำให้การฝึกโมเดลช้าและไม่สามารถใช้ประโยชน์จากการประมวลผลแบบขนาน (parallel processing) ของคอมพิวเตอร์ได้อย่างเต็มที่
การกำเนิดของ Transformer และกลไก Attention
ทุกอย่างเปลี่ยนไปเมื่อมีงานวิจัย “Attention Is All You Need” นำเสนอสถาปัตยกรรม Transformer ซึ่งปฏิวัติวงการ AI ด้วยการยกเลิกการพึ่งพา RNNs โดยสิ้นเชิง
หัวใจสำคัญของ Transformer คือกลไกที่เรียกว่า Attention mechanism หรือกลไกการใส่ใจ ซึ่งช่วยให้โมเดลสามารถพิจารณาข้อมูลทั้งหมดในประโยคได้พร้อมกัน แทนที่จะทีละคำ
กลไกนี้ทำให้โมเดลรู้ว่าคำแต่ละคำในประโยคนั้นมีความสัมพันธ์หรือเกี่ยวโยงกับคำอื่นๆ อย่างไร ช่วยให้ AI เข้าใจบริบทของประโยคได้อย่างลึกซึ้งและแม่นยำยิ่งขึ้น
กลไก Self-Attention คือหัวใจสำคัญ
ภายใน Attention mechanism ยังมีกลไกย่อยที่ทรงพลังยิ่งกว่า นั่นคือ Self-Attention กลไกนี้ทำให้คำแต่ละคำในประโยคสามารถ “มองหา” คำอื่นๆ ที่เกี่ยวข้องในประโยคเดียวกัน เพื่อสร้างความเข้าใจบริบทของตัวเอง
ตัวอย่างเช่น ในประโยค “เขาเห็นมันวางอยู่บนโต๊ะ” คำว่า “มัน” จะใช้ Self-Attention เพื่อหาว่า “มัน” ในที่นี้หมายถึงอะไร อาจจะย้อนกลับไปดูคำว่า “หนังสือ” ที่พูดถึงไปก่อนหน้า ทำให้โมเดลเข้าใจว่า “มัน” คือ “หนังสือ” นั่นเอง
ความสามารถในการประมวลผลทุกคำในประโยคพร้อมกันนี้เองที่ปลดล็อกศักยภาพของการประมวลผลแบบ parallel processing ทำให้การฝึกโมเดลรวดเร็วขึ้นอย่างมหาศาล และจัดการกับ long-term dependencies ได้อย่างมีประสิทธิภาพ
ผลลัพธ์อันยิ่งใหญ่และการขับเคลื่อน AI สู่ยุคใหม่
Transformer ไม่ได้เป็นเพียงนวัตกรรมทางทฤษฎี แต่เป็นพื้นฐานสำคัญที่นำไปสู่การพัฒนาโมเดล AI อันโด่งดังมากมาย เช่น BERT, GPT (Generative Pre-trained Transformer) และโมเดลภาษาขนาดใหญ่อื่นๆ ที่เราใช้งานกันอยู่ทุกวันนี้
การมาของ Transformer ทำให้ AI มีความสามารถในการเข้าใจและสร้างภาษาได้อย่างเป็นธรรมชาติมากขึ้น สามารถแปลภาษา สรุปความ ตอบคำถาม และแม้กระทั่งเขียนโค้ดได้ ด้วยพลังที่เพิ่มขึ้นนี้ AI จึงไม่ได้เป็นเพียงเครื่องมือ แต่เป็นผู้ช่วยที่ชาญฉลาดซึ่งเข้ามามีบทบาทสำคัญในชีวิตประจำวันของเราอย่างแท้จริง การเดินทางของ AI ยังคงดำเนินต่อไป โดยมี Transformer เป็นหนึ่งในหมุดหมายสำคัญที่พลิกโฉมวงการไปตลอดกาล