AI มองเห็นโลกอย่างไร: ทำความรู้จักกับสมองกลผู้เชี่ยวชาญด้านภาพ
คอมพิวเตอร์กับการทำความเข้าใจภาพถ่ายอาจฟังดูเป็นเรื่องซับซ้อน แต่ทุกวันนี้ปัญญาประดิษฐ์หรือ AI ก้าวหน้าไปมาก จนสามารถ “มองเห็น” และตีความสิ่งที่อยู่ในภาพได้เก่งกาจไม่แพ้สายตามนุษย์ เบื้องหลังความมหัศจรรย์นี้คือเทคโนโลยีที่เรียกว่า Convolutional Neural Networks หรือที่รู้จักกันในชื่อย่อว่า CNNs
ก่อนหน้านี้ เครือข่ายประสาทเทียมแบบดั้งเดิม (ANNs) ก็พอใช้ได้กับข้อมูลที่เป็นตัวเลขหรือข้อความ แต่พอมาเจอกับภาพถ่าย ความท้าทายก็เพิ่มขึ้นหลายเท่าตัว เพราะภาพหนึ่งภาพมีข้อมูลมหาศาล และที่สำคัญคือ ANNs มักจะมองข้ามความสัมพันธ์เชิงพื้นที่ของพิกเซล ซึ่งเป็นกุญแจสำคัญในการระบุวัตถุต่าง ๆ
แต่ CNNs ถูกออกแบบมาเพื่อแก้ปัญหานี้โดยเฉพาะ เปรียบเสมือนสมองที่ถูกฝึกมาให้เชี่ยวชาญด้านการประมวลผลภาพ
หัวใจของการมองเห็นของ AI: Convolution Operation
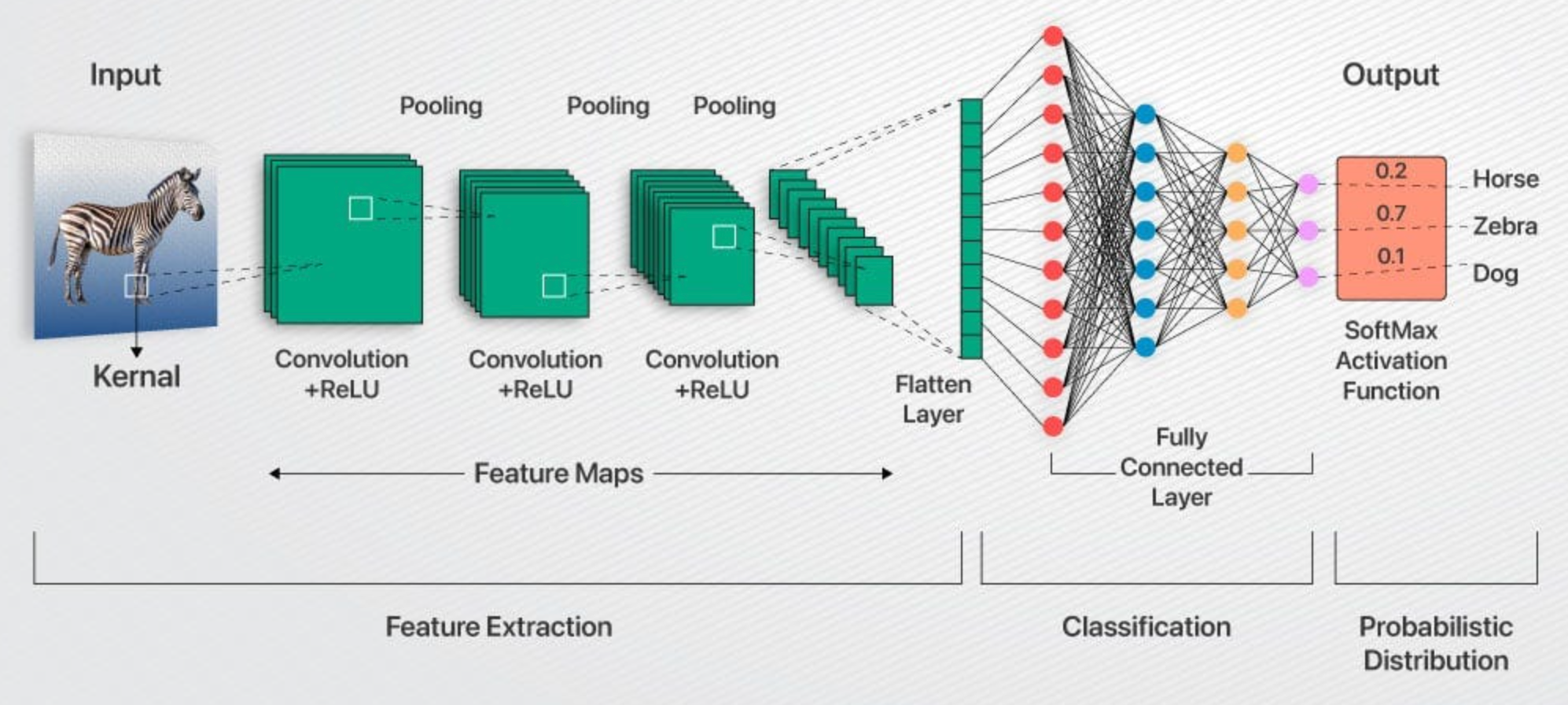
ลองนึกภาพว่าคอมพิวเตอร์ไม่ได้มองเห็นภาพทั้งหมดในคราวเดียว แต่จะค่อย ๆ สแกนไปทีละส่วนเล็ก ๆ คล้ายกับการที่เราเลื่อนแว่นขยายไปบนรูปภาพเพื่อดูรายละเอียด
นี่คือหลักการของ Convolution Operation ซึ่งเป็นหัวใจสำคัญของ CNNs โดยจะมีการใช้สิ่งที่เรียกว่า ฟิลเตอร์ (Filter) หรือ เคอร์เนล (Kernel) ซึ่งเป็นเหมือนแว่นขยายขนาดเล็ก ๆ ที่มีค่าตัวเลขกำหนดอยู่ภายใน
ฟิลเตอร์นี้จะเลื่อนไปบนภาพทีละนิด ๆ เพื่อทำการคำนวณแบบง่าย ๆ ในแต่ละจุดของการสแกน เพื่อค้นหา คุณลักษณะเด่น (Features) ต่าง ๆ เช่น ขอบ รูปร่าง หรือพื้นผิวต่าง ๆ ในภาพ
ผลลัพธ์จากการสแกนด้วยฟิลเตอร์แต่ละตัวจะกลายเป็น แผนที่คุณลักษณะ (Feature Map) ซึ่งแสดงให้เห็นว่าฟิลเตอร์นั้นตรวจจับคุณลักษณะบางอย่างเจอที่ตำแหน่งไหนในภาพบ้าง ยิ่งมีฟิลเตอร์มากเท่าไหร่ ก็ยิ่งจับคุณลักษณะที่ซับซ้อนได้มากขึ้นเท่านั้น
ขั้นตอนสำคัญอื่น ๆ ใน CNN
หลังจากที่ผ่านการทำ Convolution มาแล้ว ภาพจะถูกส่งต่อให้ชั้นอื่น ๆ เพื่อการประมวลผลที่ลึกซึ้งยิ่งขึ้น
ฟังก์ชันกระตุ้น (Activation Function) เช่น ReLU (Rectified Linear Unit) จะถูกนำมาใช้เพื่อเพิ่มความซับซ้อนให้กับการคำนวณ ทำให้โมเดลสามารถเรียนรู้รูปแบบที่ไม่เป็นเชิงเส้นได้ ซึ่งสำคัญมากในการทำความเข้าใจความสัมพันธ์ที่ซับซ้อนในภาพ
ถัดมาคือ ชั้นพูลลิ่ง (Pooling Layer) ส่วนใหญ่จะใช้ Max Pooling ซึ่งมีหน้าที่ในการลดขนาดของแผนที่คุณลักษณะลงอย่างมีประสิทธิภาพ คล้ายกับการบีบอัดข้อมูลโดยเลือกเก็บเฉพาะข้อมูลที่สำคัญที่สุด การทำเช่นนี้ไม่เพียงช่วยลดภาระการคำนวณ แต่ยังทำให้โมเดลทนทานต่อการเปลี่ยนแปลงเล็กน้อยในตำแหน่งของวัตถุอีกด้วย
เมื่อถึงจุดหนึ่ง แผนที่คุณลักษณะสองมิติที่ได้จะถูกแปลงให้เป็นข้อมูลแบบหนึ่งมิติในขั้นตอนที่เรียกว่า แฟลตเทนนิ่ง (Flattening) เพื่อเตรียมข้อมูลให้พร้อมสำหรับการส่งต่อไปยังชั้นถัดไป
สุดท้าย ข้อมูลจะเข้าสู่ Fully Connected Layers ซึ่งคล้ายกับเครือข่ายประสาทเทียมแบบดั้งเดิม โดยชั้นเหล่านี้จะรับข้อมูลที่คุณลักษณะเด่นที่ถูกสกัดออกมาแล้ว และใช้มันในการตัดสินใจขั้นสุดท้าย เช่น การจำแนกประเภทของวัตถุในภาพ โดยมี Softmax เป็นชั้นเอาต์พุตที่แปลงผลลัพธ์ให้เป็นความน่าจะเป็นของแต่ละประเภท
ทำไม CNN ถึงฉลาดนัก?
ความสามารถที่โดดเด่นของ CNNs อยู่ที่การเรียนรู้แบบลำดับชั้น เริ่มต้นจากการเรียนรู้คุณลักษณะพื้นฐานอย่างเส้นและขอบ จากนั้นก็ค่อย ๆ นำคุณลักษณะเหล่านั้นมารวมกันเป็นคุณลักษณะที่ซับซ้อนขึ้น เช่น ส่วนประกอบของใบหน้า หรือรูปร่างของวัตถุ ทำให้ AI สามารถเข้าใจภาพได้ในลักษณะเดียวกับที่มนุษย์มองเห็นและตีความข้อมูลภาพ
เทคโนโลยี CNNs ได้เข้ามาพลิกโฉมการประมวลผลภาพอย่างสิ้นเชิง การประยุกต์ใช้มีมากมายมหาศาล ตั้งแต่ การจำแนกภาพ (Image Classification) เช่น การระบุว่าในภาพเป็นแมวหรือหมา ไปจนถึง การตรวจจับวัตถุ (Object Detection) ในรถยนต์ไร้คนขับ การรู้จำใบหน้า (Facial Recognition) ในระบบรักษาความปลอดภัย หรือแม้กระทั่งช่วยวิเคราะห์ภาพทางการแพทย์เพื่อตรวจหาโรค นี่คือบทบาทสำคัญที่ทำให้ AI สามารถ “มองเห็น” และทำความเข้าใจโลกใบนี้ได้อย่างชาญฉลาดและมีประสิทธิภาพยิ่งขึ้น