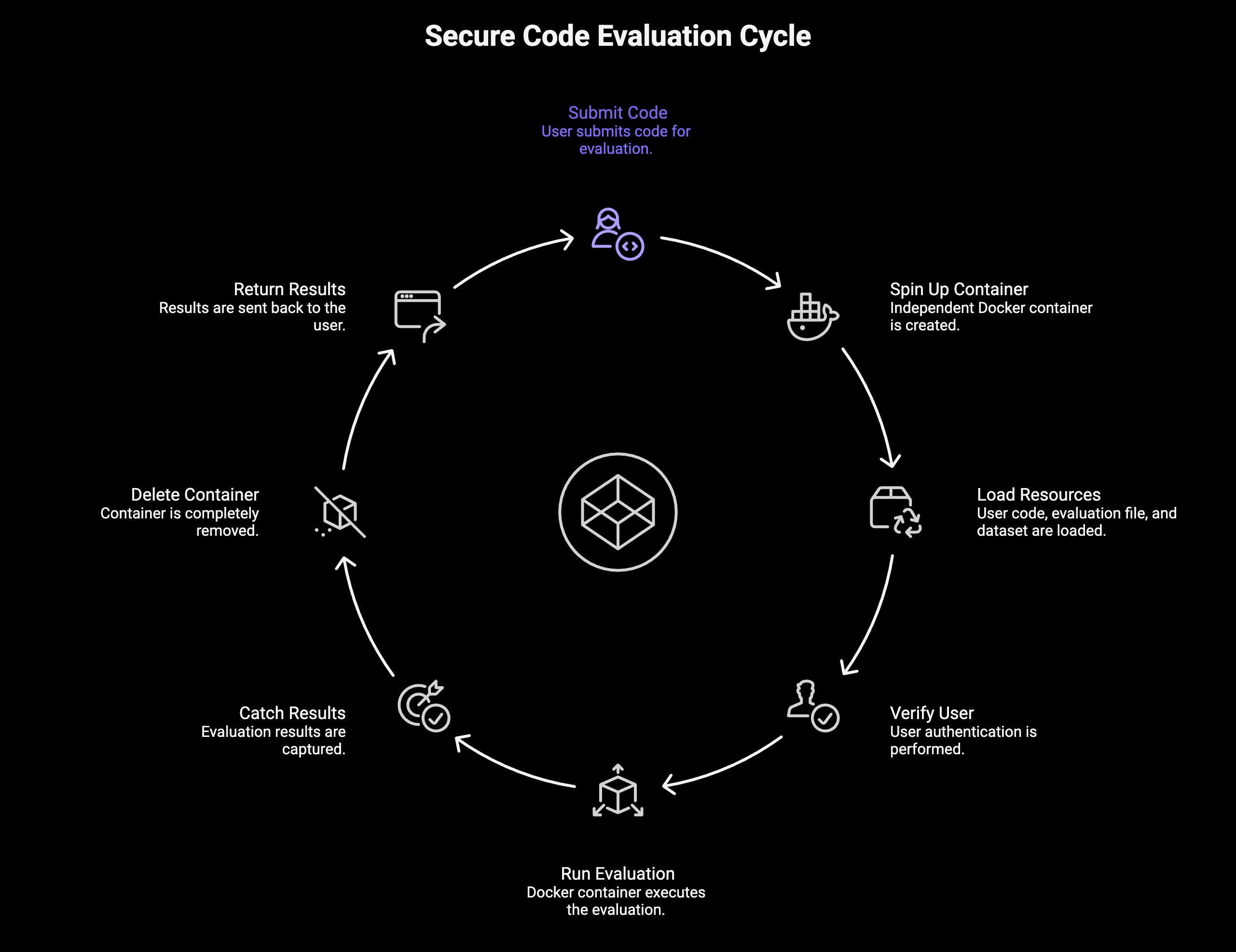
ปลดล็อกศักยภาพ ML: ก้าวข้ามกำแพงทฤษฎีสู่การลงมือทำจริง
การเรียนรู้ Machine Learning (ML) ในปัจจุบันมักสร้างความท้าทายที่น่าแปลกใจให้หลายคน ทั้งที่เข้าใจทฤษฎีได้อย่างลึกซึ้ง สามารถอธิบายการทำงานของ backpropagation หรือเขียนโค้ดสำหรับ gradient descent ได้อย่างแม่นยำ แต่เมื่อต้องเผชิญหน้ากับปัญหาในโลกความเป็นจริง กลับรู้สึกเหมือนติดอยู่ในเขาวงกต
นี่ไม่ใช่เรื่องแปลก เพราะระบบการศึกษา ML ส่วนใหญ่มักเน้นหนักไปที่ความเข้าใจเชิงทฤษฎีและโมเดลทางคณิตศาสตร์มากเกินไป จนละเลยการเตรียมความพร้อมสำหรับการนำไปใช้งานจริง
ทำไมทฤษฎีแน่น แต่ใช้งานจริงไม่ได้?
หลายครั้งที่ผู้เรียน ML รู้สึกว่าสามารถทำข้อสอบได้คะแนนดีเยี่ยม หรือเข้าใจแนวคิดทางทฤษฎีต่างๆ ได้อย่างทะลุปรุโปร่ง แต่พอถึงเวลาที่ต้องเริ่มโปรเจกต์ของตัวเอง กลับไม่รู้ว่าจะเริ่มต้นจากตรงไหนดี
ช่องว่างขนาดใหญ่ระหว่างการศึกษาในห้องเรียนกับการทำงานจริงคือสิ่งที่เรียกว่า “ความยุ่งเหยิงตรงกลาง” (messy middle) ซึ่งเป็นช่วงที่ข้อมูลไม่ได้ถูกจัดเตรียมมาอย่างสมบูรณ์แบบ ปัญหาไม่ได้ถูกกำหนดไว้อย่างชัดเจน และสภาพแวดล้อมในการทำงานก็ไม่ได้พร้อมใช้งานเสมอไป
ประสบการณ์แบบนี้ทำให้หลายคนท้อแท้และตั้งคำถามกับความรู้ที่ได้มา
ปัญหาที่มองไม่เห็นในการเรียนรู้ ML
เบื้องหลังความท้าทายนี้ มีปัญหาหลายประการที่การเรียนรู้ ML แบบเดิมๆ มักจะมองข้ามไป
อันดับแรกคือ การตั้งค่าสภาพแวดล้อม ผู้เริ่มต้นหลายคนต้องเสียเวลาหลายชั่วโมง บางครั้งเป็นวัน เพื่อติดตั้งไลบรารี กำหนดค่าสภาพแวดล้อมใน Jupyter Notebooks หรือแก้ไขปัญหา dependency ต่างๆ กว่าจะได้เริ่มเขียนโค้ด ML จริงๆ ก็แทบจะหมดแรงเสียก่อน
ประการที่สองคือ ข้อมูลในโลกจริง แตกต่างจากข้อมูลตัวอย่างในตำราเรียนอย่างสิ้นเชิง ข้อมูลจริงมักจะสกปรก มีค่าว่าง ความผิดปกติ หรือรูปแบบที่ซับซ้อน ทำให้การจัดการข้อมูล หรือที่เรียกว่า data preprocessing กลายเป็นงานที่ท้าทายและใช้เวลาส่วนใหญ่ของโปรเจกต์ ซึ่งมักถูกสอนเพียงผิวเผินในชั้นเรียน
สุดท้ายคือ การกำหนดปัญหา ในโลกจริง ปัญหาไม่ได้ถูกนำเสนอมาพร้อมกับข้อมูลที่สะอาดและเป้าหมายที่ชัดเจนเสมอไป ผู้ปฏิบัติงานต้องใช้ทักษะในการตีความ ทำความเข้าใจ และกำหนดขอบเขตของปัญหาด้วยตัวเอง
ทางออกที่ช่วยเชื่อมช่องว่าง
เพื่อแก้ปัญหาช่องว่างระหว่างทฤษฎีและการปฏิบัติ สิ่งที่จำเป็นคือแพลตฟอร์มการเรียนรู้ที่เน้นประสบการณ์จริง ตั้งแต่การเริ่มต้นโปรเจกต์ไปจนถึงการแก้ปัญหาที่ซับซ้อน
แพลตฟอร์มที่ตอบโจทย์นี้ควรมีลักษณะดังนี้: สภาพแวดล้อมพร้อมใช้งาน ผู้เรียนสามารถเริ่มต้นทำงานได้ทันทีโดยไม่ต้องกังวลเรื่องการติดตั้งใดๆ เน้นไปที่ โจทย์ที่เหมือนจริง ที่ต้องใช้ข้อมูลที่ “สกปรก” หรือไม่สมบูรณ์ และมีคำแนะนำที่จะพาผู้เรียนผ่านขั้นตอนการทำความสะอาดข้อมูล (data cleaning) รวมถึงการเลือกโมเดลที่เหมาะสม
ที่สำคัญคือการสอนให้ผู้เรียนเข้าใจว่างาน ML ส่วนใหญ่ไม่ได้อยู่ที่การสร้างโมเดลที่ซับซ้อนที่สุด แต่คือการ จัดการและทำความเข้าใจข้อมูล ซึ่งเป็นหัวใจสำคัญของการทำงานในสายอาชีพนี้ การฝึกฝนด้วยโจทย์ที่ท้าทายแต่มีโครงสร้างและคำแนะนำ จะช่วยเสริมสร้าง ความมั่นใจ และ ทักษะการแก้ปัญหา ที่จำเป็นสำหรับการเป็นผู้เชี่ยวชาญ ML อย่างแท้จริง
การพัฒนาทักษะ Machine Learning ต้องอาศัยทั้งความรู้เชิงทฤษฎีที่แข็งแกร่ง และการลงมือปฏิบัติจริงอย่างสม่ำเสมอ การฝึกฝนกับโจทย์ที่สะท้อนโลกแห่งความเป็นจริงจะช่วยให้เข้าใจกระบวนการทั้งหมดได้อย่างถ่องแท้ และเตรียมพร้อมสำหรับการนำความรู้ไปใช้สร้างสรรค์นวัตกรรมใหม่ๆ ได้อย่างเต็มที่