แกะรอยความอัจฉริยะของ AI: ทำความรู้จัก “Transformer” และ “Attention”
ทุกวันนี้เราคงคุ้นเคยกับการสนทนากับ AI ไม่ว่าจะเป็นแชทบอทที่ตอบคำถามได้อย่างชาญฉลาด หรือโปรแกรมที่สามารถสร้างข้อความได้ราวกับมนุษย์เขียนเอง เบื้องหลังความสามารถอันน่าทึ่งเหล่านี้ มีเทคโนโลยีหลักที่เรียกว่า Transformer และกลไกสำคัญที่เรียกว่า Attention ซ่อนอยู่ ซึ่งได้ปฏิวัติวงการปัญญาประดิษฐ์ไปอย่างสิ้นเชิง
แกนหลักแห่งการประมวลผลภาษา: Transformer คืออะไร?
ก่อนหน้านี้ การประมวลผลภาษาธรรมชาติ (NLP) มักจะใช้โครงข่ายประสาทเทียมแบบวนซ้ำ (Recurrent Neural Network – RNN) ซึ่งทำงานโดยการประมวลผลคำทีละคำตามลำดับ ทำให้เกิดข้อจำกัดในการจัดการกับประโยคยาวๆ เพราะข้อมูลที่อยู่ไกลกันจะถูกจดจำได้ยาก
แต่ Transformer ได้เข้ามาเปลี่ยนวิธีการนี้ มันคือสถาปัตยกรรมโมเดลที่ถูกออกแบบมาให้สามารถประมวลผลข้อมูลพร้อมกันในคราวเดียว แทนที่จะเรียงลำดับ การทำงานแบบขนานนี้ช่วยให้โมเดลสามารถเข้าใจบริบทและความสัมพันธ์ของคำในประโยคได้ดีขึ้นมาก ไม่ว่าจะสั้นหรือยาวแค่ไหนก็ตาม
สิ่งนี้เองที่ทำให้ Transformer กลายเป็นรากฐานสำคัญของโมเดลภาษาขนาดใหญ่ (LLMs) อย่าง GPT ซึ่งย่อมาจาก Generative Pre-trained Transformer โดยชื่อก็บอกอยู่แล้วว่าสร้างมาจากสถาปัตยกรรมนี้นั่นเอง
หัวใจสำคัญของการเข้าใจบริบท: กลไก Attention ทำงานอย่างไร?
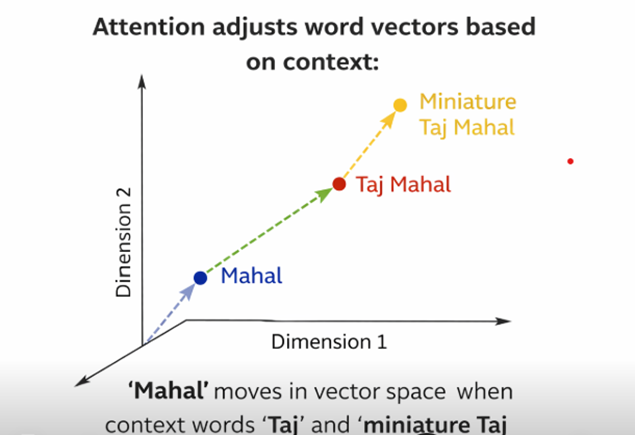
หากเปรียบเทียบกับมนุษย์ การอ่านหรือฟังใครสักคน เราไม่ได้จดจ่ออยู่กับทุกคำเท่ากันหมด แต่จะเลือก ให้ความสนใจ ไปยังคำหรือวลีที่สำคัญและเกี่ยวข้องเพื่อทำความเข้าใจบริบท กลไก Attention ใน Transformer ก็ทำหน้าที่คล้ายกัน
มันช่วยให้โมเดลสามารถ “มองเห็น” และ “ประเมินความสำคัญ” ของคำแต่ละคำในประโยคที่กำลังประมวลผลอยู่ ว่าคำเหล่านั้นมีความเชื่อมโยงหรือส่งผลต่อคำปัจจุบันมากน้อยแค่ไหน ตัวอย่างเช่น เมื่อโมเดลกำลังแปลประโยค “เขาไปธนาคารเพื่อถอนเงิน” หากโมเดลกำลังประมวลผลคำว่า “เงิน” กลไก Attention จะช่วยให้มันรู้ว่าคำว่า “ธนาคาร” เป็นคำที่สำคัญและเกี่ยวข้องกับ “เงิน” มากกว่าคำว่า “เขา” หรือ “ไป”
ความสามารถในการเลือกโฟกัสนี้ทำให้โมเดลไม่จำเป็นต้องประมวลผลข้อมูลทั้งหมดเท่ากัน มันสามารถให้น้ำหนักความสำคัญกับส่วนที่จำเป็นจริงๆ ช่วยให้การตีความมีความแม่นยำและลึกซึ้งยิ่งขึ้น
เจาะลึกกลไก Attention: Query, Key และ Value
เพื่อทำความเข้าใจว่า Attention ทำงานอย่างไรในเชิงเทคนิค ลองนึกภาพว่าโมเดลมีการสร้างตัวแทนของคำ (หรือที่เรียกว่า vector) ขึ้นมา 3 แบบสำหรับแต่ละคำ ได้แก่ Query (Q), Key (K) และ Value (V)
- Query (Q) เหมือนกับ “คำถาม” ที่คำปัจจุบันกำลังถาม เพื่อหาคำอื่นๆ ที่เกี่ยวข้อง
- Key (K) เหมือน “กุญแจ” หรือ “คำตอบ” ที่คำอื่นๆ มี เพื่อให้คำปัจจุบันสามารถจับคู่และค้นหาความเกี่ยวข้องได้
- Value (V) คือ “เนื้อหา” หรือ “ข้อมูล” จริงๆ ของคำนั้นๆ
กลไก Attention จะคำนวณคะแนนความเกี่ยวข้องระหว่าง Query ของคำปัจจุบัน กับ Key ของคำอื่นๆ ทุกคำในประโยค ยิ่งคะแนนสูงเท่าไหร่ ก็แปลว่าคำนั้นๆ มีความเกี่ยวข้องกับคำปัจจุบันมากเท่านั้น จากนั้น โมเดลจะนำคะแนนเหล่านี้มาถ่วงน้ำหนักกับ Value ของคำอื่นๆ เพื่อสร้างตัวแทนของคำปัจจุบันที่รวมเอาบริบทจากคำที่เกี่ยวข้องเข้ามาด้วย
นอกจากนี้ ยังมี Multi-Head Attention ที่จะแบ่งกระบวนการนี้ออกเป็นหลาย “หัว” เพื่อให้โมเดลสามารถมองหาความเกี่ยวข้องได้จากหลายแง่มุมพร้อมๆ กัน ทำให้การทำความเข้าใจบริบทมีความซับซ้อนและละเอียดอ่อนยิ่งขึ้นไปอีก
และเพื่อไม่ให้โมเดลลืมลำดับของคำ ซึ่งเป็นสิ่งสำคัญในภาษา ระบบจึงมีการ “เข้ารหัสตำแหน่ง” (Positional Encoding) เข้ามาช่วย เพื่อบอกโมเดลว่าคำแต่ละคำอยู่ในตำแหน่งไหนในประโยค
พลังของความเข้าใจที่เปลี่ยนโลก
การรวมกันของสถาปัตยกรรม Transformer ที่ประมวลผลแบบขนานได้รวดเร็ว และกลไก Attention ที่ช่วยให้โมเดลเข้าใจบริบทและความสัมพันธ์ของคำได้อย่างลึกซึ้ง ทำให้ AI สามารถสร้างสรรค์ผลงานด้านภาษาได้อย่างน่าทึ่ง นี่คือเบื้องหลังสำคัญที่ทำให้เราได้เห็นการก้าวกระโดดของเทคโนโลยี AI อย่างที่เราเป็นอยู่ในปัจจุบัน และแน่นอนว่ามันจะยังคงพัฒนาและสร้างสิ่งใหม่ๆ ให้เราได้เห็นต่อไปในอนาคตอันใกล้