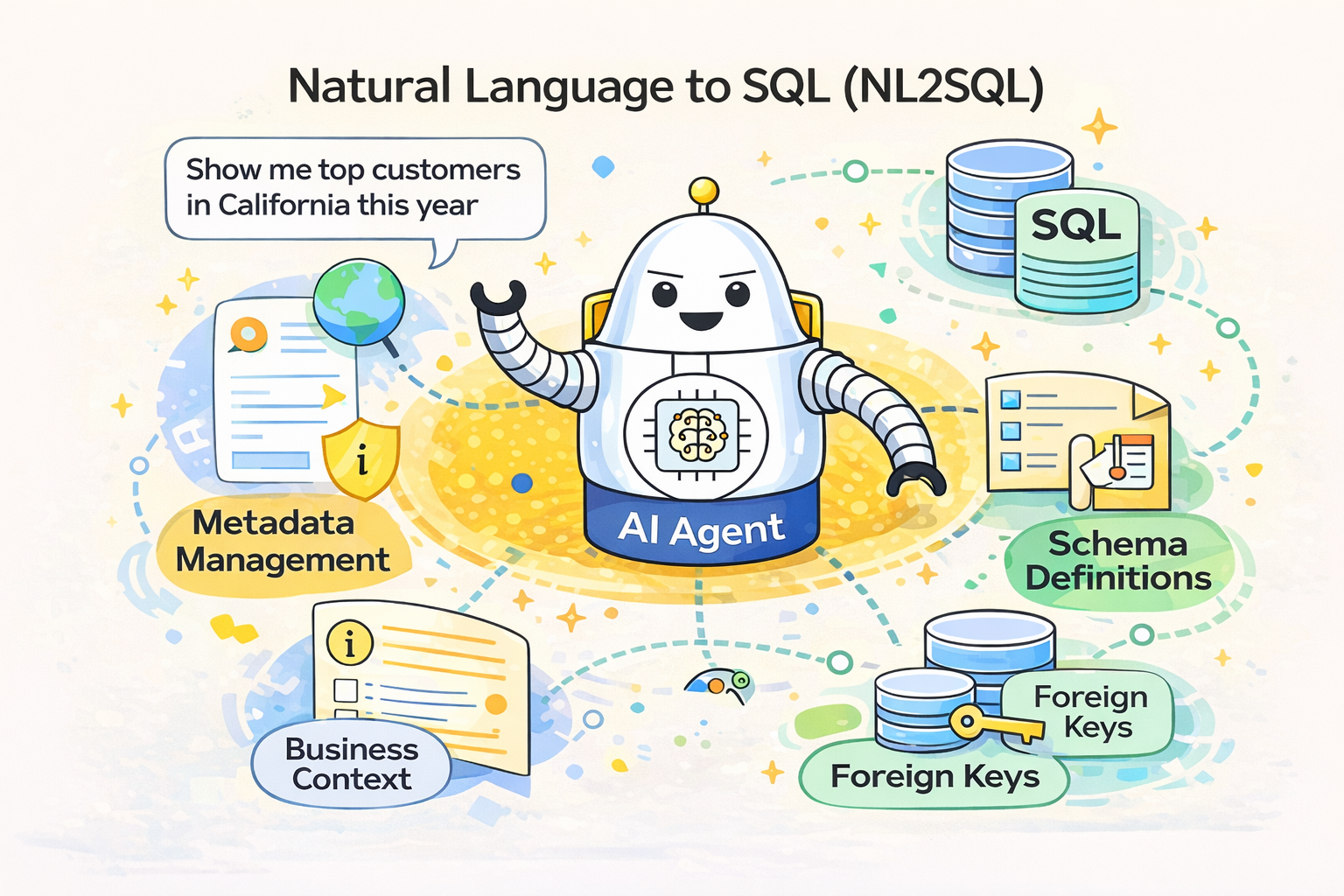
ปลดล็อกพลัง NL2SQL: กุญแจสำคัญไม่ได้อยู่ที่ AI แต่มันคือ ‘เมตาเดตา’ ที่คุณมี
เทคโนโลยี Natural Language to SQL (NL2SQL) กำลังเป็นที่พูดถึงอย่างกว้างขวางในโลกของข้อมูลยุคใหม่ ลองจินตนาการถึงความสะดวกสบายในการถามคำถามเกี่ยวกับข้อมูลในคลังของคุณด้วยภาษาพูดง่ายๆ เช่น “แสดงยอดขายรวมของเดือนที่แล้วในภูมิภาคเอเชียตะวันออกเฉียงใต้” แล้ว AI ก็แปลงคำถามนั้นเป็นโค้ด SQL ที่ซับซ้อนและดึงผลลัพธ์มาให้ทันที นี่คืออนาคตที่ใกล้แค่เอื้อม และบริษัทเทคโนโลยียักษ์ใหญ่อย่าง Snowflake, Databricks, Microsoft และ Google ต่างก็กระโดดเข้าสู่สนามนี้พร้อมกับโซลูชันของตัวเอง
เทคโนโลยีเหล่านี้สัญญาว่าจะทำให้ทุกคนเข้าถึงข้อมูลได้ง่ายขึ้น ไม่ต้องพึ่งพาผู้เชี่ยวชาญด้าน SQL อีกต่อไป ลดภาระงานของทีมข้อมูล และเร่งการตัดสินใจทางธุรกิจได้ทันท่วงที แต่ท่ามกลางความตื่นเต้นนี้ มีปัญหาคอขวดหนึ่งที่หลายองค์กรมักมองข้ามไป ซึ่งอาจฉุดรั้งประสิทธิภาพของ NL2SQL ไว้ นั่นคือ คุณภาพของเมตาเดตา
ปัญหาคอขวดที่แท้จริง ไม่ใช่ AI แต่เป็น ‘เมตาเดตา’
หลายคนอาจคิดว่าความท้าทายหลักอยู่ที่การพัฒนาโมเดล AI ให้ฉลาดพอ แต่ความจริงแล้ว โมเดล AI ในปัจจุบันมีความสามารถในการแปลงภาษาธรรมชาติเป็น SQL ได้อย่างน่าทึ่งแล้ว สิ่งที่ AI ขาดคือ ความเข้าใจเชิงบริบท ของข้อมูลในฐานข้อมูลของคุณ AI สามารถเข้าใจโครงสร้างทางไวยากรณ์ของ SQL ได้ดี แต่ไม่สามารถเข้าใจ “ความหมาย” ของตาราง คอลัมน์ หรือความสัมพันธ์ระหว่างข้อมูลได้อย่างลึกซึ้ง หากปราศจากคำแนะนำที่ชัดเจน
นี่คือจุดที่ เมตาเดตา (Metadata) หรือ “ข้อมูลเกี่ยวกับข้อมูล” เข้ามามีบทบาทสำคัญ เมตาเดตาที่ดีจะทำหน้าที่เป็นพจนานุกรมและคู่มือสำหรับ AI ช่วยให้ AI สามารถตีความคำถามจากภาษาธรรมชาติ และเชื่อมโยงกับข้อมูลที่ถูกต้องในฐานข้อมูลได้อย่างแม่นยำ
เมตาเดตาแบบไหนที่ทำให้ AI งง?
ลองนึกภาพว่ากำลังพยายามสอนใครสักคนให้เข้าใจแผนที่สมบัติ แต่แผนที่นั้นเขียนด้วยตัวย่อที่ไม่มีคำอธิบาย ชื่อสถานที่เปลี่ยนแปลงบ่อยๆ และไม่ระบุทิศทางที่ชัดเจน นั่นคือสิ่งที่เกิดขึ้นกับ AI เมื่อเผชิญกับเมตาเดตาที่ไม่ดี
ปัญหาทั่วไปที่พบบ่อยได้แก่:
- ไม่ครบถ้วนและล้าสมัย: โครงสร้างฐานข้อมูลเปลี่ยนแปลงอยู่เสมอ แต่คำอธิบายเมตาเดตาไม่ได้อัปเดตตาม ทำให้ข้อมูลเกี่ยวกับข้อมูลไม่ตรงกับความเป็นจริง
- ชื่อเรียกไม่สอดคล้องกัน: คอลัมน์ที่หมายถึงสิ่งเดียวกันอาจมีหลายชื่อ เช่น
cust_id,customerID,ClientIDซึ่งสร้างความสับสนให้ AI - ขาดบริบทและความหมาย: คอลัมน์ชื่อ
AMTอาจหมายถึง “จำนวนเงิน” แต่ AI จะไม่รู้จนกว่าจะมีคำอธิบายที่ชัดเจน หรือTXN_DTคือ “วันที่ทำรายการ” - ความคลุมเครือ: คำว่า “รายได้” อาจมีความหมายต่างกันไปในแต่ละตาราง (รายได้รวม, รายได้สุทธิ) หากไม่มีคำจำกัดความที่ชัดเจน
- ช่องว่างทางความหมาย (Semantic Gap): AI เข้าใจภาษาโปรแกรมได้ดี แต่ไม่เข้าใจความหมายทางธุรกิจของข้อมูล เช่น “ผู้ใช้งานที่ใช้งานอยู่” หมายถึงอะไรในบริบทนี้
สร้างรากฐานที่แข็งแกร่งให้ AI ฉลาดขึ้น
การลงทุนในเมตาเดตาที่มีคุณภาพจึงเป็นสิ่งจำเป็นเพื่อให้ NL2SQL ทำงานได้เต็มศักยภาพ นี่คือสิ่งที่องค์กรควรพิจารณา:
- จัดทำ Data Governance และ Data Catalog: สร้างระบบและกระบวนการในการจัดการ เมตาเดตา อย่างเป็นระบบ มีเครื่องมือ Data Catalog ที่รวบรวมและจัดเก็บข้อมูลเกี่ยวกับตาราง คอลัมน์ และความสัมพันธ์ต่างๆ อย่างมีโครงสร้าง
- มีผู้รับผิดชอบ (Data Stewards): แต่งตั้งบุคลากรหรือทีมที่รับผิดชอบโดยตรงในการดูแลรักษาและปรับปรุง คุณภาพของเมตาเดตา ให้ถูกต้องและทันสมัยอยู่เสมอ
- เพิ่มคำอธิบายที่ชัดเจนและสอดคล้อง: ทุกคอลัมน์ ทุกตาราง ควรมีคำอธิบายที่เข้าใจง่าย และใช้ภาษาที่สอดคล้องกันทั่วทั้งองค์กร
- สร้าง Semantic Layer: พัฒนาชั้นความหมายที่เชื่อมโยงชื่อคอลัมน์และตารางทางเทคนิค เข้ากับภาษาทางธุรกิจที่ผู้ใช้งานคุ้นเคย ช่วยให้ AI แปลงคำถามได้แม่นยำยิ่งขึ้น
- อัปเดตอย่างต่อเนื่อง: เมตาเดตาไม่ใช่งานที่ทำครั้งเดียวจบ ต้องมีการดูแลรักษาและอัปเดตอยู่เสมอเพื่อให้สะท้อนสถานะปัจจุบันของข้อมูล
การให้ความสำคัญกับ เมตาเดตา คือการลงทุนที่คุ้มค่า มันจะช่วยให้องค์กรของคุณสามารถดึงศักยภาพสูงสุดของเทคโนโลยี NL2SQL ออกมาได้อย่างแท้จริง ทำให้การเข้าถึงและใช้งานข้อมูลเป็นเรื่องง่ายสำหรับทุกคน และขับเคลื่อนการตัดสินใจทางธุรกิจได้อย่างมีประสิทธิภาพมากยิ่งขึ้น