การจำแนกโทเค็นใน NLP: กุญแจสำคัญสู่ความเข้าใจภาษามนุษย์อย่างลึกซึ้ง
คอมพิวเตอร์เข้าใจภาษามนุษย์ที่ซับซ้อนได้อย่างไร? หนึ่งในเทคนิคเบื้องหลังที่สำคัญและทรงพลังคือ การจำแนกโทเค็น (Token Classification)
นี่คือกระบวนการที่สอนให้ระบบปัญญาประดิษฐ์ (AI) สามารถระบุและเข้าใจความหมายหรือหน้าที่ของแต่ละส่วนประกอบเล็กๆ ในประโยค เปรียบเสมือนการแยกชิ้นส่วนจิ๊กซอว์ เพื่อให้ระบบสามารถประกอบภาพรวมและเข้าใจเนื้อหาได้อย่างถ่องแท้
ถือเป็นรากฐานสำคัญที่ทำให้แอปพลิเคชันภาษาธรรมชาติ (NLP) จำนวนมากทำงานได้อย่างชาญฉลาดในชีวิตประจำวันของเรา
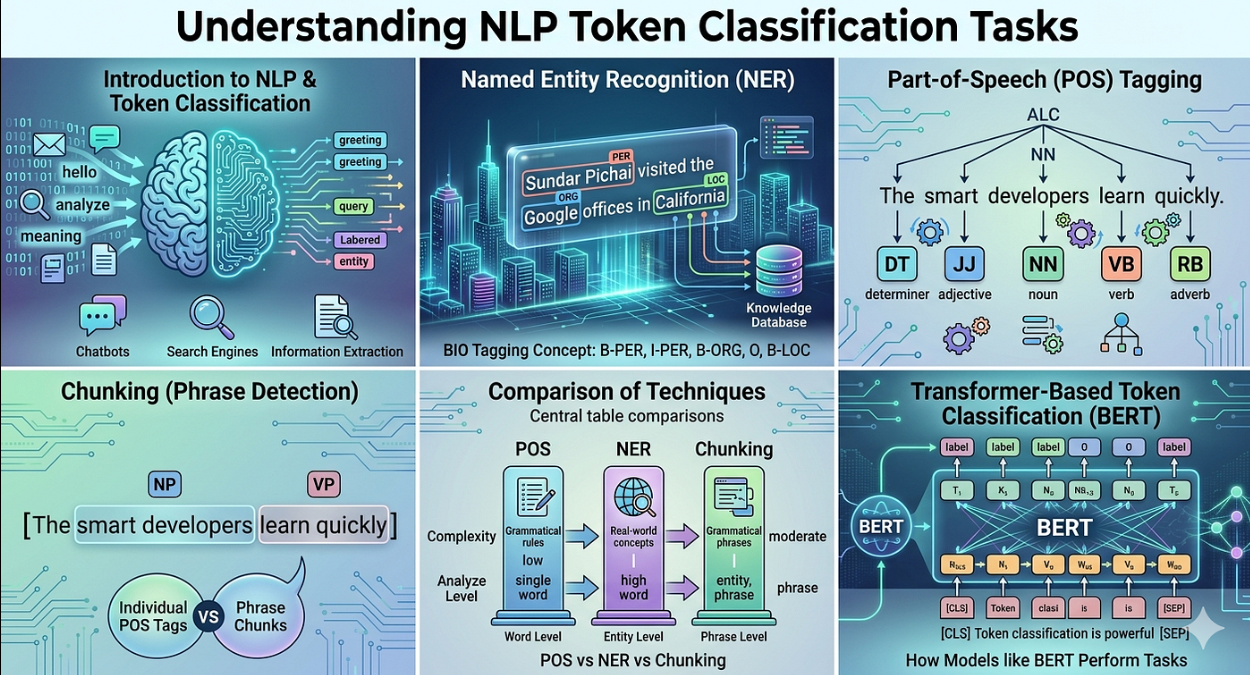
หัวใจของการจำแนกโทเค็น: อะไรคือ ‘โทเค็น’ และทำไมต้อง ‘จำแนก’?
ในบริบทของ NLP คำว่า โทเค็น คือหน่วยย่อยที่สุดของข้อความที่ระบบจะประมวลผล
หน่วยเหล่านี้อาจเป็นคำเดียวๆ
ส่วนหนึ่งของคำ หรือแม้แต่ตัวอักษรหนึ่งตัว ขึ้นอยู่กับวิธีการแบ่งโทเค็นที่ใช้
การจำแนกโทเค็นคือการกำหนด ป้ายกำกับ (labels) ให้กับโทเค็นเหล่านั้น
ป้ายกำกับนี้จะบ่งบอกถึงประเภทหรือหน้าที่ของโทเค็นในบริบทของประโยคหรือข้อความนั้นๆ
ลองนึกภาพประโยคว่า “กรุงเทพมหานคร เป็นเมืองหลวงของประเทศไทย”
ระบบจะมองแต่ละคำเป็นโทเค็น และการจำแนกโทเค็นจะบอกว่า “กรุงเทพมหานคร” คือ “สถานที่” และ “ประเทศไทย” ก็คือ “สถานที่” เช่นกัน
งานประเภทนี้มักถูกเรียกว่า การติดป้ายลำดับ (Sequence Labeling)
เพราะระบบต้องประมวลผลและให้ป้ายกำกับโทเค็นตามลำดับที่ปรากฏในข้อความ ทำให้เข้าใจความสัมพันธ์และโครงสร้างของภาษาได้ดียิ่งขึ้น
กระบวนการทำงานเบื้องหลังความฉลาดของภาษา
ก่อนที่คอมพิวเตอร์จะสามารถจำแนกโทเค็นได้อย่างมีประสิทธิภาพ จำเป็นต้องผ่านขั้นตอนการเตรียมข้อมูลที่สำคัญ
โดยเริ่มจากการ แบ่งโทเค็น (Tokenization) ข้อความดิบให้เป็นหน่วยย่อยๆ ที่พร้อมสำหรับการประมวลผล
จากนั้นข้อมูลเหล่านี้จะถูกจัดเตรียมในรูปแบบที่เหมาะสม เพื่อนำไปใช้ฝึกฝนโมเดลปัญญาประดิษฐ์
หัวใจสำคัญอยู่ที่ โมเดลปัญญาประดิษฐ์ ที่ได้รับการออกแบบมาโดยเฉพาะสำหรับงานนี้
ในปัจจุบัน Transformer models อย่าง BERT หรือ RoBERTa ถือเป็นกลุ่มโมเดลที่ได้รับความนิยมและมีประสิทธิภาพสูงมาก
โมเดลเหล่านี้มีความสามารถโดดเด่นในการทำความเข้าใจ บริบท ของคำในประโยคได้อย่างยอดเยี่ยม
สิ่งนี้ช่วยให้การจำแนกโทเค็นมีความแม่นยำและลึกซึ้งยิ่งขึ้น ไม่ใช่แค่การมองคำโดดๆ
เมื่อโมเดลได้รับการฝึกฝนด้วยชุดข้อมูลขนาดใหญ่ที่ผ่านการติดป้ายกำกับมาอย่างดีแล้ว ก็จะสามารถเรียนรู้และทำนายป้ายกำกับของโทเค็นใหม่ๆ ที่ไม่เคยเห็นมาก่อนได้อย่างอัตโนมัติ
ความถูกต้องของโมเดลจะถูกประเมินด้วย ตัวชี้วัด (metrics) ต่างๆ เช่น ความแม่นยำ (Accuracy), ความเที่ยงตรง (Precision), การระลึก (Recall), และ F1-score
ประโยชน์อันน่าทึ่ง: การประยุกต์ใช้ในโลกจริง
การจำแนกโทเค็นเป็นพื้นฐานสำคัญที่ขับเคลื่อนแอปพลิเคชัน NLP มากมายที่เราใช้งานอยู่ในชีวิตประจำวัน
ตัวอย่างที่โดดเด่นคือ การรู้จำเอนทิตีที่ถูกตั้งชื่อ (Named Entity Recognition หรือ NER)
เทคนิคนี้ช่วยให้ AI สามารถระบุชื่อคน องค์กร สถานที่ วันที่ ปริมาณ หรือสกุลเงินต่างๆ ในข้อความได้อย่างแม่นยำ ทำให้ระบบสามารถดึงข้อมูลสำคัญออกมาได้อย่างรวดเร็วเพื่อนำไปใช้งานต่อ
อีกตัวอย่างคือ การระบุชนิดของคำ (Part-of-Speech Tagging หรือ POS Tagging)
เป็นการกำหนดหน้าที่ทางไวยากรณ์ของแต่ละคำ เช่น คำนาม คำกริยา คำคุณศัพท์ สิ่งนี้ช่วยให้ระบบเข้าใจโครงสร้างและไวยากรณ์ของประโยค ซึ่งเป็นพื้นฐานสำหรับการแปลภาษาหรือการวิเคราะห์ประโยคที่ซับซ้อน
นอกจากนี้ยังมีการใช้งานในการ เติมช่องว่าง (Slot Filling) ในระบบสนทนาอัตโนมัติ (Chatbot)
เพื่อดึงข้อมูลเฉพาะที่ผู้ใช้ต้องการ เช่น ชื่อสินค้า วันที่จอง หรือสถานที่ปลายทาง ทำให้ Chatbot สามารถตอบสนองความต้องการของผู้ใช้ได้อย่างตรงจุด
รวมถึงการตรวจจับสแปม การสร้างดัชนีข้อมูลใน Search Engine และแม้แต่การสรุปข้อความ
การจำแนกโทเค็นช่วยให้คอมพิวเตอร์ “อ่าน” และ “เข้าใจ” เนื้อหาได้อย่างลึกซึ้ง และประมวลผลข้อมูลภาษาจำนวนมหาศาลได้อย่างมีประสิทธิภาพ
อนาคตของการจำแนกโทเค็นยังคงเต็มไปด้วยนวัตกรรมและความท้าทาย ตั้งแต่การรับมือกับคำศัพท์ใหม่ๆ ภาษาถิ่น หรือความกำกวมของภาษา ไปจนถึงการพัฒนาโมเดลที่สามารถทำงานได้หลายภาษาพร้อมกัน เทคนิคนี้จะยังคงเป็นกุญแจสำคัญในการปลดล็อกศักยภาพของภาษาธรรมชาติ ทำให้คอมพิวเตอร์สามารถสื่อสารและช่วยเหลือมนุษย์ได้อย่างไร้รอยต่อยิ่งขึ้น