เลือก Vector Database อย่างไรให้เหมาะกับ RAG System ของคุณ
ในโลกของการพัฒนาระบบ Retrieval Augmented Generation หรือ RAG ที่กำลังมาแรง การเลือก Vector Database ที่เหมาะสมถือเป็นหัวใจสำคัญ เพราะมันคือที่เก็บข้อมูลเวกเตอร์ที่แปลงมาจากเอกสารหรือข้อความ เพื่อให้ AI สามารถดึงข้อมูลที่เกี่ยวข้องกลับมาใช้ได้รวดเร็วและแม่นยำ
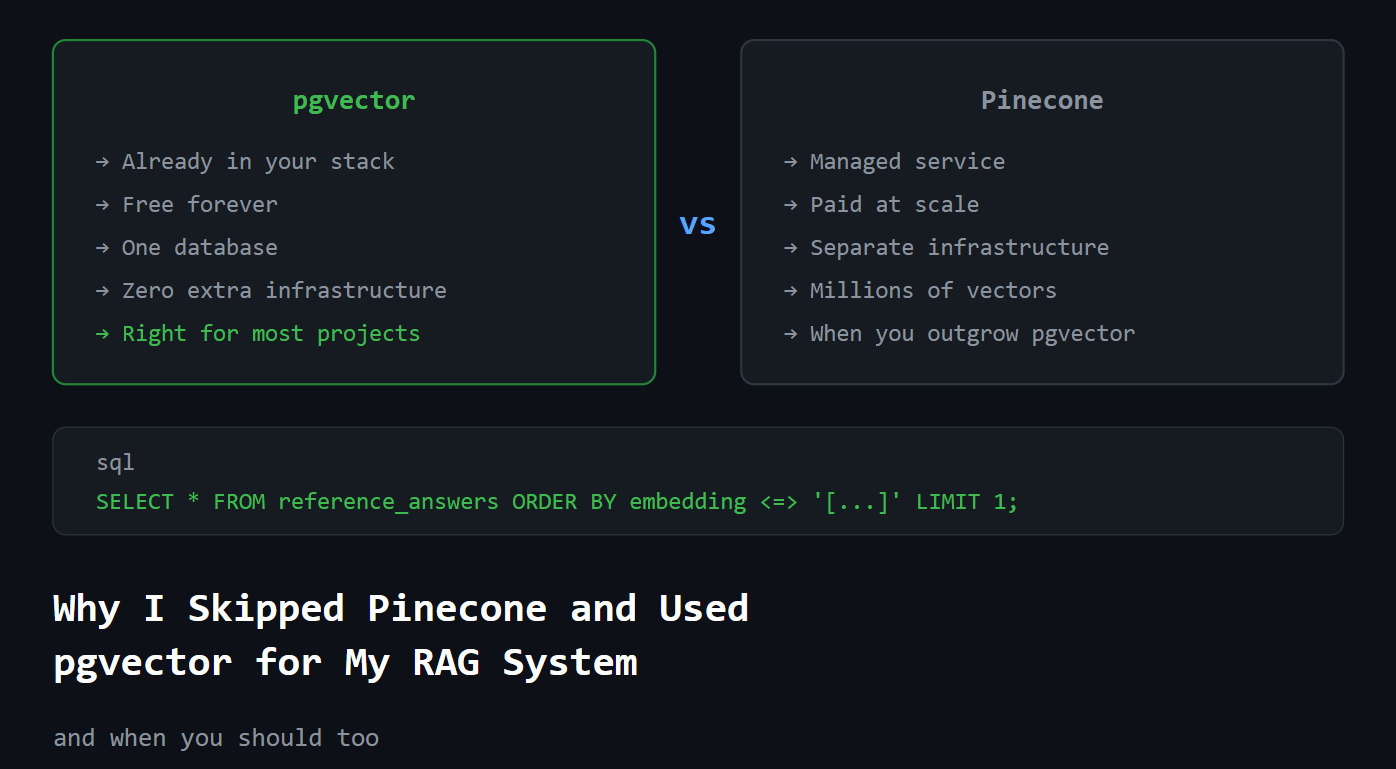
หลายคนอาจคิดถึงบริการเฉพาะทางอย่าง Pinecone เป็นอันดับแรก แต่ความจริงแล้ว ยังมีตัวเลือกที่น่าสนใจและอาจจะคุ้มค่ากว่ามาก นั่นก็คือ pgvector ซึ่งเป็นส่วนเสริมของ PostgreSQL ที่เราคุ้นเคยกันดี
ทำความรู้จัก PGVector: ตัวเลือกที่คุ้นเคยแต่ทรงพลัง
pgvector คือ ส่วนขยาย ที่เพิ่มความสามารถในการจัดเก็บและค้นหาเวกเตอร์เข้ามาใน PostgreSQL ซึ่งเป็น Relational Database ที่ใช้งานกันอย่างแพร่หลายอยู่แล้ว นี่คือข้อดีที่ทำให้ pgvector กลายเป็นตัวเลือกที่น่าสนใจอย่างยิ่งสำหรับระบบ RAG
ประการแรกเรื่อง ต้นทุน การใช้ pgvector ทำให้เราสามารถ ประหยัดค่าใช้จ่าย ได้อย่างมหาศาล เพราะไม่ต้องเสียเงินไปกับบริการฐานข้อมูลเวกเตอร์เฉพาะทางเพิ่มเติม หากมี PostgreSQL ใช้งานอยู่แล้ว ก็เหมือนได้มาฟรี ๆ
ความ เรียบง่าย คืออีกหนึ่งจุดเด่น การจัดการข้อมูลทุกอย่างให้อยู่ในฐานข้อมูลเดียว ทั้งข้อมูลหลักและเวกเตอร์ ช่วยลดความซับซ้อนในการดูแลระบบ ไม่ต้องคอยซิงค์ข้อมูลระหว่างฐานข้อมูลสองตัว ลดความปวดหัวเรื่อง ความสอดคล้องของข้อมูล ได้ดีเยี่ยม
นอกจากนี้ PostgreSQL ยังเป็น Open-source ทำให้เรามีอิสระในการควบคุม ปรับแต่ง และสามารถ Scale ได้ตามความต้องการของโปรเจกต์ โดยไม่ต้องกังวลเรื่องการถูกผูกมัดกับผู้ให้บริการรายใดรายหนึ่ง
เรื่อง ประสิทธิภาพ ก็ไม่ใช่ปัญหา pgvector สามารถทำงานได้ดีเยี่ยมด้วยการรองรับ ดัชนี HNSW ซึ่งช่วยให้การค้นหาเวกเตอร์ขนาดใหญ่หลายล้านรายการเป็นไปอย่างรวดเร็วและมีประสิทธิภาพ เหมาะสำหรับโปรเจกต์ RAG ทั่วไปที่ไม่ได้ต้องการความเร็วระดับเสี้ยววินาที
เหตุผลที่หลายคนอาจมองข้าม Pinecone (และ Vector Database เฉพาะทางอื่นๆ)
แม้ว่า Pinecone และ Vector Database เฉพาะทางอื่น ๆ จะมีชื่อเสียง แต่ก็มีหลายเหตุผลที่อาจทำให้ไม่ได้เป็นตัวเลือกแรกสำหรับทุกโปรเจกต์ โดยเฉพาะอย่างยิ่งสำหรับสตาร์ทอัพหรือโปรเจกต์ที่มีงบประมาณจำกัด
หนึ่งในข้อกังวลหลักคือเรื่อง ค่าใช้จ่าย บริการเหล่านี้มักคิดค่าใช้จ่ายตามปริมาณข้อมูลและการใช้งาน ซึ่งอาจสูงขึ้นอย่างรวดเร็ว โดยเฉพาะเมื่อมีการ อัปเดตหรือลบข้อมูลบ่อยครั้ง ทำให้เกิด “churn” หรือการเปลี่ยนแปลงของข้อมูลเวกเตอร์จำนวนมาก
อีกประเด็นคือ ความซับซ้อน ในการดูแลระบบ การมีฐานข้อมูลเวกเตอร์แยกต่างหาก หมายถึงต้องมีส่วนประกอบเพิ่มเติมในสถาปัตยกรรมของระบบ ต้องจัดการการเชื่อมต่อ การซิงค์ข้อมูล และการดูแลรักษาเพิ่มเติม ซึ่งเพิ่มภาระให้กับทีมพัฒนา
การที่ข้อมูลหลักกับข้อมูลเวกเตอร์อยู่คนละที่ ทำให้เกิดความท้าทายในการ รักษาความถูกต้องและเป็นปัจจุบันของข้อมูล การเปลี่ยนแปลงข้อมูลในฐานข้อมูลหลัก ต้องแน่ใจว่าข้อมูลเวกเตอร์ที่เกี่ยวข้องก็ถูกอัปเดตตามไปด้วยเสมอ
และสุดท้ายคือความเสี่ยงเรื่อง Vendor Lock-in เมื่อเราลงทุนกับบริการเฉพาะทางไปแล้ว การย้ายไปใช้บริการอื่นในอนาคตอาจทำได้ยากและมีค่าใช้จ่ายสูง ซึ่งอาจเป็นอุปสรรคต่อการเติบโตและการปรับตัวของระบบในระยะยาว
เมื่อไหร่ที่ Pinecone (หรือ Vector Database เฉพาะทาง) เป็นทางเลือกที่ดีกว่า
แน่นอนว่า Vector Database เฉพาะทางก็มีจุดแข็งที่ pgvector อาจจะยังไปไม่ถึง และเหมาะกับบางสถานการณ์เป็นพิเศษ
หากโปรเจกต์ต้องจัดการกับ ข้อมูลเวกเตอร์มหาศาล ในระดับพันล้านรายการ หรือต้องการ ความเร็วในการค้นหาที่เหนือกว่า ชนิดที่ต้องตอบสนองในระดับ Millisecond หน่วยเล็ก ๆ เท่านั้น Pinecone หรือบริการอื่น ๆ ที่ออกแบบมาเพื่อสิ่งนี้โดยเฉพาะ อาจตอบโจทย์ได้ดีกว่า
นอกจากนี้ หากทีมพัฒนาต้องการ ความสะดวกสบาย ของบริการแบบ Managed Service ที่มีการดูแลรักษา ปรับขนาด และจัดการทุกอย่างให้เรียบร้อย โดยไม่ต้องการยุ่งเกี่ยวกับการติดตั้งหรือดูแล Infrastructure ด้วยตัวเอง ตัวเลือกเหล่านี้ก็เป็นทางออกที่ดี
บางกรณีที่ต้องการ ฟีเจอร์ขั้นสูงเฉพาะทาง ที่ pgvector ยังไม่มี หรือเมื่อไม่มีโครงสร้างพื้นฐานของ PostgreSQL อยู่แล้ว การเริ่มต้นด้วย Vector Database เฉพาะทางก็เป็นทางเลือกที่สมเหตุสมผล
การตัดสินใจเลือกใช้ Vector Database ตัวไหน ควรพิจารณาจาก ขนาดของโปรเจกต์ งบประมาณ ความซับซ้อน ที่ยอมรับได้ และ ความต้องการด้านประสิทธิภาพ เป็นสำคัญ การทำความเข้าใจข้อดีข้อเสียของแต่ละตัวเลือก จะช่วยให้เราสามารถสร้างระบบ RAG ที่มีประสิทธิภาพและยั่งยืนได้อย่างแท้จริง