ปลดล็อกขีดจำกัด AI: เมื่อ “ความจำ” ของโมเดลไม่ใช่ปัญหาอีกต่อไป
AI ยุคใหม่ โดยเฉพาะ โมเดลภาษาขนาดใหญ่ (LLMs) ที่เราคุ้นเคยกันดี มีความสามารถน่าทึ่งมากมาย ไม่ว่าจะเป็นการเขียน การแปล หรือการสร้างสรรค์สิ่งต่างๆ
แต่เคยสงสัยไหมว่าทำไมบางครั้ง AI ถึงเหมือนจะ “ลืม” สิ่งที่เคยพูดคุยไปก่อนหน้า
หรือไม่สามารถประมวลผลข้อมูลยาวๆ เช่น เอกสารหลายสิบหน้า ได้อย่างต่อเนื่องและมีประสิทธิภาพเท่าที่ควร
นี่คือสิ่งที่นักวิจัยเรียกว่า “กำแพงแห่งบริบท” หรือ Context Length ซึ่งเป็นข้อจำกัดใหญ่ที่ AI ต้องเผชิญมานานนับทศวรรษ และเป็นตัวจำกัดพัฒนาการของมันมาตลอด
ทำความเข้าใจ “กำแพงแห่งบริบท”
กำแพงแห่งบริบทคือขีดจำกัดว่า AI จะสามารถจดจำและประมวลผลข้อมูลในคราวเดียวได้มากน้อยแค่ไหน
ลองนึกภาพว่าคุณกำลังอ่านหนังสือ แต่สมองสามารถจำรายละเอียดที่เชื่อมโยงกันได้แค่ไม่กี่หน้าล่าสุดเท่านั้น หากเกินจากนั้น ข้อมูลเก่าๆ ก็จะเริ่มเลือนหายไป
AI ก็คล้ายกัน เมื่อข้อมูลที่ป้อนเข้าไปมีความยาวมากเกินไป AI จะเริ่มสูญเสียความสามารถในการเชื่อมโยงและทำความเข้าใจความสัมพันธ์ของข้อมูลทั้งหมด
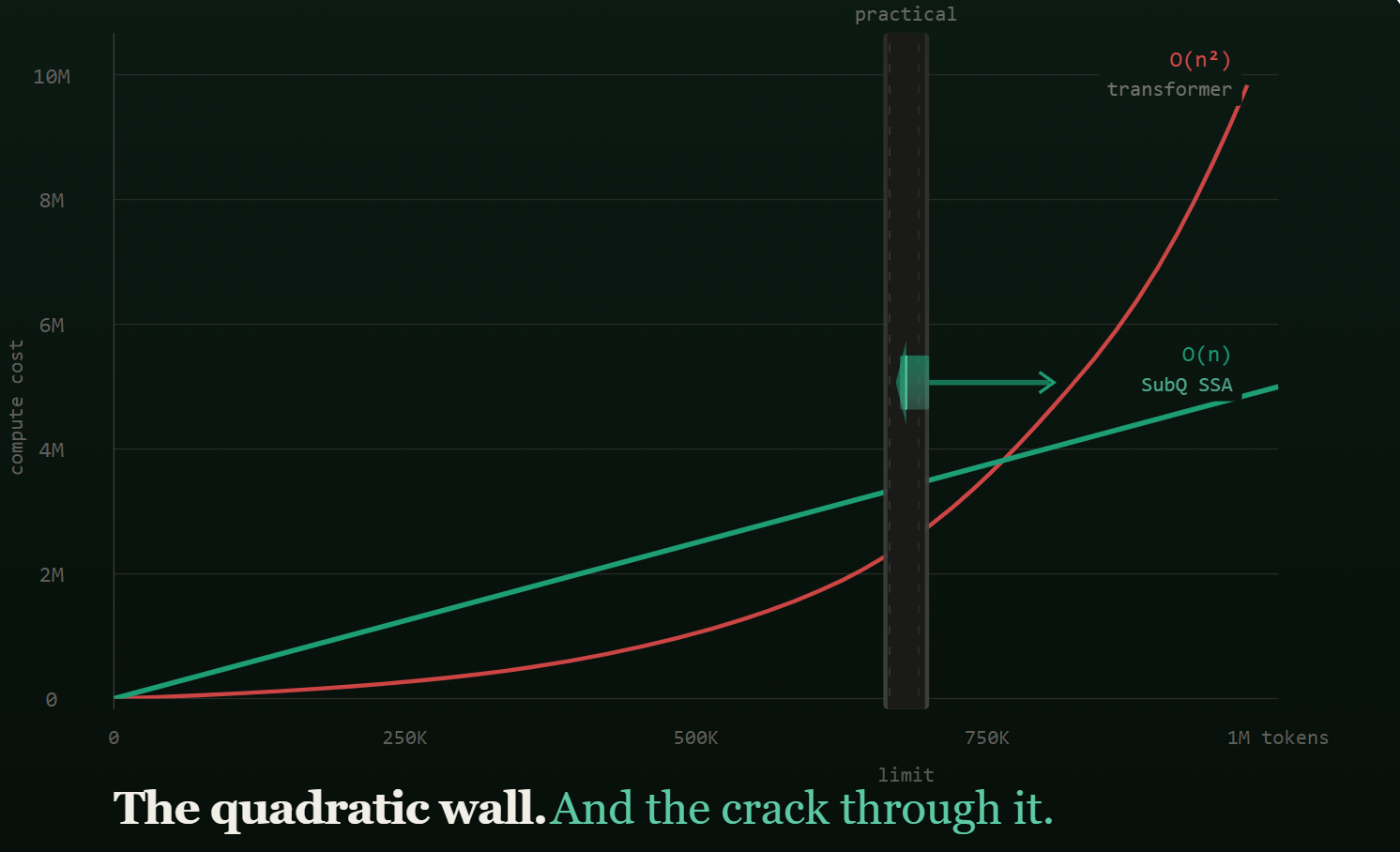
ปัญหาหลักเกิดจาก สถาปัตยกรรมแบบ Transformer ซึ่งเป็นหัวใจสำคัญของ LLMs ส่วนใหญ่ในปัจจุบัน
กลไกที่เรียกว่า Attention Mechanism แม้จะช่วยให้ AI เข้าใจความสัมพันธ์ระหว่างคำต่างๆ ได้อย่างยอดเยี่ยม แต่ก็มีข้อเสียใหญ่
คือการคำนวณที่ต้องใช้ทรัพยากรมหาศาลแบบ การประมวลผลเชิงควอดราติก (Quadratic Scaling)
หมายความว่า ยิ่งบริบทข้อมูลยาวขึ้นเท่าไร พลังประมวลผลและเวลาที่ต้องใช้ก็จะเพิ่มขึ้นแบบทวีกำลัง
ทำให้การสร้าง AI ที่สามารถประมวลผลบริบทที่ยาวมากๆ เช่น หนังสือทั้งเล่ม หรือการสนทนาที่ยืดเยื้อ เป็นเรื่องที่แทบจะเป็นไปไม่ได้ในทางปฏิบัติ เพราะมันมีค่าใช้จ่ายด้านคอมพิวเตอร์และเวลาสูงลิบลิ่ว
การบุกทะลุกำแพงครั้งสำคัญ
ล่าสุด มีสตาร์ทอัพชื่อ SubQ (Subquadratic) ที่อ้างว่าได้คิดค้นวิธีการแก้ปัญหาทางคณิตศาสตร์นี้ได้แล้ว
พวกเขาสามารถเปลี่ยนจากการคำนวณแบบ การประมวลผลเชิงควอดราติก ที่เป็นอุปสรรคมานาน
มาเป็นการคำนวณแบบ การประมวลผลเชิงเส้นตรง (Linear Scaling) ได้สำเร็จ
การเปลี่ยนแปลงนี้ฟังดูเป็นเรื่องทางเทคนิค แต่มีความหมายใหญ่หลวงมาก
มันหมายความว่า แทนที่พลังประมวลผลจะเพิ่มขึ้นอย่างรวดเร็วเป็นสองเท่า สี่เท่า หรือแปดเท่า เมื่อข้อมูลยาวขึ้น
ตอนนี้มันจะเพิ่มขึ้นอย่างค่อยเป็นค่อยไป สอดคล้องกับความยาวของข้อมูลเท่านั้น
นี่คือการเปลี่ยนแปลงพื้นฐานที่จะปลดปล่อย AI จากข้อจำกัดด้าน “ความจำ” ที่เคยฉุดรั้งไว้ ให้ทำงานได้อย่างมีประสิทธิภาพมากขึ้นในบริบทที่ยาวกว่าเดิมหลายเท่า
อนาคตของ AI ที่ไร้ขีดจำกัด
การบุกทะลุครั้งนี้จะนำไปสู่ศักยภาพใหม่ๆ ที่น่าตื่นเต้นอย่างมหาศาล
AI จะสามารถประมวลผลข้อมูลที่มีความยาวเป็นพิเศษได้ เช่น หนังสือทั้งเล่ม บทความวิชาการยาวเหยียด หรือแม้กระทั่งชุดข้อมูลขนาดใหญ่ทั้งหมด ในคราวเดียว
ลองนึกภาพผู้ช่วย AI ที่สามารถอ่านอีเมลและเอกสารตลอดทั้งวันของคุณ และสามารถตอบคำถามที่ซับซ้อนเกี่ยวกับข้อมูลเหล่านั้นได้อย่างแม่นยำ
โดยไม่หลงลืมรายละเอียดที่กล่าวถึงไปเมื่อหลายชั่วโมงก่อน
สิ่งนี้จะช่วยให้ AI มี ความเข้าใจเชิงลึก และสามารถให้คำแนะนำที่ชาญฉลาดและรอบด้านมากขึ้น
มันจะเปิดประตูสู่การสร้าง AI ที่มีความเชี่ยวชาญเฉพาะด้าน อย่างแท้จริง
เช่น AI ด้านการแพทย์ที่ประมวลผลประวัติผู้ป่วยทั้งหมดและงานวิจัยทางการแพทย์ หรือ AI ด้านกฎหมายที่อ่านเอกสารสัญญาหลายร้อยหน้าได้อย่างละเอียดและรวดเร็ว
บางคนถึงกับมองว่านี่อาจเป็นก้าวสำคัญที่นำไปสู่การพัฒนา ปัญญาประดิษฐ์ทั่วไป (AGI) ที่แท้จริง
ที่สามารถคิดและเรียนรู้ได้เหมือนมนุษย์มากขึ้น เพราะความสามารถในการประมวลผลบริบทจำนวนมากเป็นหัวใจสำคัญของสติปัญญาและความเข้าใจที่ซับซ้อน
โลกกำลังจะได้เห็นยุคใหม่ของ AI ที่มี “ความจำ” ที่ยาวนานและเข้าใจโลกได้ลึกซึ้งกว่าที่เคยเป็นมาอย่างแน่นอน