ปลดล็อกพลัง LLM: รัน AI สุดฉลาดบนเครื่องคอมพิวเตอร์ของคุณได้อย่างไร
โลกของปัญญาประดิษฐ์กำลังก้าวหน้าไปอย่างรวดเร็ว โดยเฉพาะ Large Language Models (LLM) ที่ฉลาดล้ำ แต่หลายคนอาจคิดว่าโมเดลเหล่านี้ต้องใช้ซูเปอร์คอมพิวเตอร์ราคาแพงในการประมวลผล ความจริงแล้ว มีเทคนิคและเครื่องมือมากมายที่ช่วยให้เราสามารถรัน LLM บนคอมพิวเตอร์ส่วนตัวได้อย่างมีประสิทธิภาพ ลองมาดูกันว่าเบื้องหลังความมหัศจรรย์นี้มีอะไรซ่อนอยู่บ้าง
ลดขนาดโมเดล: ควอนไทเซชั่น (Quantization)
หนึ่งในอุปสรรคสำคัญของการรัน LLM คือขนาดของโมเดลที่ใหญ่มาก ซึ่งกินหน่วยความจำ (RAM) และพลังประมวลผลอย่างมหาศาล
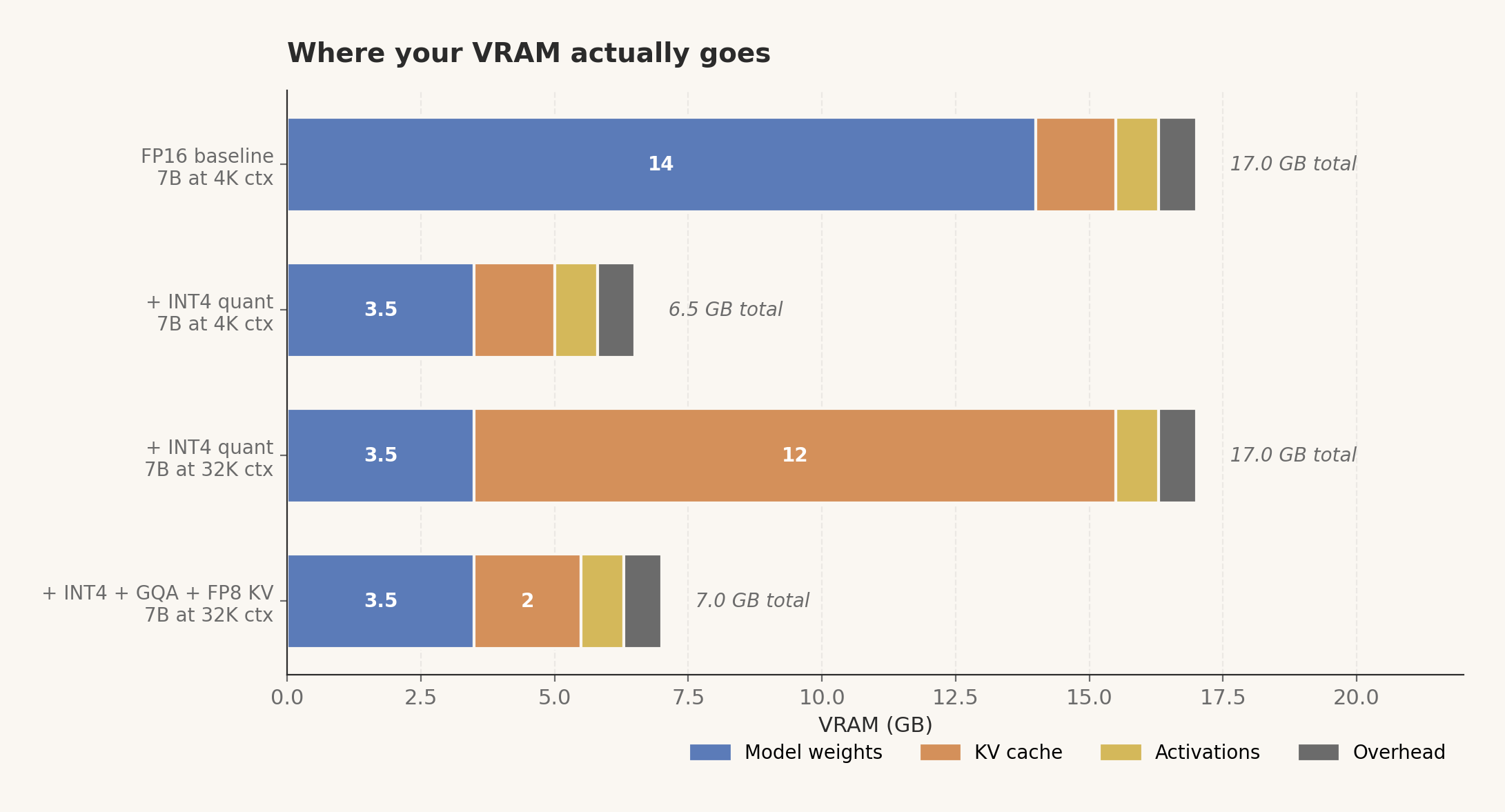
ควอนไทเซชั่น คือเทคนิคที่ช่วยลดขนาดโมเดลลงอย่างมาก โดยการลดความละเอียดของข้อมูลตัวเลขที่ใช้ในการจัดเก็บน้ำหนักของโมเดล
จากเดิมที่ใช้ตัวเลขแบบละเอียดสูง (เช่น 16-bit floating point) ก็เปลี่ยนมาใช้ตัวเลขที่หยาบขึ้น (เช่น 8-bit หรือ 4-bit integer) การทำแบบนี้ช่วย ประหยัดหน่วยความจำ ได้หลายเท่าตัว และยังช่วยให้ ประมวลผลได้เร็วขึ้น ด้วย เพราะหน่วยประมวลผลสามารถจัดการกับข้อมูลขนาดเล็กได้เร็วกว่า
สิ่งที่น่าทึ่งคือ การลดขนาดข้อมูลนี้แทบไม่ส่งผลกระทบต่อความสามารถและความฉลาดของโมเดลเลย ทำให้เราได้ LLM ที่ทำงานได้ดีบนฮาร์ดแวร์ทั่วไป
ความฉลาดในการจำ: KV Cache
เมื่อ LLM สร้างข้อความยาวๆ แต่ละคำที่สร้างขึ้นใหม่จะต้องพิจารณาทุกคำที่เคยสร้างมาก่อนหน้านี้ ซึ่งเป็นกระบวนการที่ซับซ้อนและกินเวลามาก
KV Cache (Key-Value Cache) เป็นกลไกที่เข้ามาช่วยตรงจุดนี้ โดยพื้นฐานแล้ว มันคือการ จัดเก็บข้อมูลสำคัญ ที่คำนวณไว้แล้วสำหรับคำก่อนหน้าทั้งหมด
แทนที่จะคำนวณซ้ำทุกครั้งที่สร้างคำใหม่ โมเดลก็สามารถดึงข้อมูลที่เก็บไว้ใน KV Cache มาใช้ได้เลยทันที ช่วยลดภาระการประมวลผลได้อย่างมหาศาล ทำให้ LLM สามารถ สร้างข้อความยาวๆ ได้เร็วขึ้น และ ใช้พลังงานน้อยลง โดยเฉพาะอย่างยิ่งเมื่อทำงานกับบริบทที่ยาวมากๆ
ปฏิวัติกลไกความสนใจ: Flash Attention
หัวใจสำคัญของ Transformer ซึ่งเป็นสถาปัตยกรรมหลักของ LLM คือกลไกที่เรียกว่า “Attention” หรือการให้ความสนใจกับส่วนต่างๆ ของข้อความ
อย่างไรก็ตาม กลไก Attention แบบดั้งเดิมนั้น กินหน่วยความจำมาก และ ใช้เวลาประมวลผลนาน เมื่อความยาวของข้อความเพิ่มขึ้น
Flash Attention คือการปรับปรุงกลไก Attention ให้ ฉลาดขึ้นและประหยัดยิ่งขึ้น โดยมันจะจัดเรียงลำดับการคำนวณใหม่ และใช้หน่วยความจำภายในของ GPU (SRAM) ที่เร็วกว่าหน่วยความจำหลัก (HBM) ได้อย่างมีประสิทธิภาพมากขึ้น
ผลลัพธ์คือการลดการเข้าถึงหน่วยความจำหลัก ลดเวลาประมวลผล และ ลดการใช้หน่วยความจำลงอย่างมาก ทำให้รันโมเดลที่ใหญ่ขึ้นหรือจัดการกับข้อความที่ยาวขึ้นได้ดีกว่าเดิม
สถาปัตยกรรมทางเลือกใหม่: Mamba และ MoE
นอกจากการปรับปรุงเทคนิคภายในแล้ว ยังมีการพัฒนา สถาปัตยกรรมโมเดลใหม่ๆ เพื่อให้ LLM ทำงานได้ดีขึ้นบนฮาร์ดแวร์ทั่วไปอีกด้วย
Mamba เป็นสถาปัตยกรรมใหม่ที่กำลังมาแรง ซึ่งแตกต่างจาก Transformer ตรงที่มันสามารถประมวลผลข้อมูลได้แบบเส้นตรง (linear scaling) ตามความยาวของลำดับข้อมูล
นี่หมายความว่า Mamba สามารถ จัดการกับข้อความยาวๆ ได้อย่างมีประสิทธิภาพ มากกว่า Transformer ที่มักจะใช้หน่วยความจำและเวลาประมวลผลเพิ่มขึ้นแบบยกกำลังสองเมื่อความยาวของข้อความเพิ่มขึ้น Mamba จึงเป็นความหวังใหม่สำหรับ LLM ที่ต้องการความเร็วและประหยัดหน่วยความจำ
ส่วน Mixture of Experts (MoE) เป็นอีกแนวคิดที่น่าสนใจ โมเดล MoE จะมี “ผู้เชี่ยวชาญ” หลายคน ซึ่งแต่ละคนเชี่ยวชาญในงานหรือข้อมูลประเภทใดประเภทหนึ่งโดยเฉพาะ
เมื่อโมเดลได้รับข้อมูลเข้า ผู้เชี่ยวชาญเพียงไม่กี่คนเท่านั้นที่จะถูกเรียกใช้งาน ทำให้แม้ว่าโมเดลโดยรวมจะมีขนาดใหญ่มาก แต่ในแต่ละครั้งที่ประมวลผล ใช้ทรัพยากรน้อยลงมาก คล้ายกับการมีทีมงานขนาดใหญ่ แต่เรียกใช้เฉพาะผู้ที่เกี่ยวข้องกับงานนั้นๆ เท่านั้น
ตัวกลางแห่งการใช้งานจริง: LLM Runtimes
เทคนิคทั้งหมดที่กล่าวมานี้จะไร้ประโยชน์ หากไม่มีเครื่องมือที่จะทำให้เราสามารถนำไปใช้งานได้จริงบนคอมพิวเตอร์ของเรา
LLM Runtimes หรือเฟรมเวิร์กการรัน LLM คือซอฟต์แวร์ที่รวมเอาเทคนิคการเพิ่มประสิทธิภาพเหล่านี้เข้าไว้ด้วยกัน ทำให้การรัน LLM บนฮาร์ดแวร์ทั่วไปเป็นเรื่องที่ง่ายขึ้น
ตัวอย่างที่โดดเด่นและเป็นที่รู้จักกันดีคือ llama.cpp ซึ่งเป็นโปรเจกต์โอเพนซอร์สที่มุ่งเน้นการรัน LLM บน CPU เป็นหลัก ทำให้ผู้ใช้งานสามารถรันโมเดลขนาดใหญ่ได้อย่างน่าทึ่งบนเครื่องคอมพิวเตอร์ธรรมดาๆ โดยไม่จำเป็นต้องมี GPU ประสิทธิภาพสูง
ยังมีเครื่องมืออื่นๆ เช่น vLLM, TensorRT-LLM หรือ MLC LLM ที่ออกแบบมาเพื่อดึงประสิทธิภาพสูงสุดจาก GPU และฮาร์ดแวร์อื่นๆ แต่ llama.cpp ได้พิสูจน์แล้วว่าพลังของ LLM ไม่ได้จำกัดอยู่แค่ในศูนย์ข้อมูลขนาดใหญ่เท่านั้น
ด้วยนวัตกรรมเหล่านี้ การเข้าถึงและใช้งาน LLM ประสิทธิภาพสูงบนเครื่องคอมพิวเตอร์ส่วนตัวจึงไม่ใช่เรื่องไกลตัวอีกต่อไป นับเป็นยุคที่ทุกคนสามารถเป็นส่วนหนึ่งของการปฏิวัติ AI ได้อย่างแท้จริง