พลังของการจัดกลุ่มข้อมูลแบบนุ่มนวล: ทำความรู้จักกับ GMMs และ EM Algorithm
การจัดกลุ่ม (Clustering) คือเทคนิคสำคัญในการทำความเข้าใจชุดข้อมูลขนาดใหญ่ ช่วยจำแนกข้อมูลที่มีลักษณะคล้ายกันให้อยู่รวมกัน K-Means จัดกลุ่มแบบ “แข็ง” (Hard Clustering) ที่ข้อมูลอยู่กลุ่มเดียวอย่างชัดเจน แต่ Gaussian Mixture Models (GMMs) ซับซ้อนกว่า ให้ภาพการกระจายตัวข้อมูลลึกซึ้งยิ่งขึ้น
GMMs คืออะไร? ทำไมต้องใช้?
GMMs คือโมเดล ความน่าจะเป็น (Probabilistic Model) สมมติว่าชุดข้อมูลมาจากผลรวมของการกระจายตัวแบบ เกาส์เซียน (Gaussian Distribution) หลายกลุ่ม
แต่ละกลุ่มเกาส์เซียนมีสามพารามิเตอร์: ค่าเฉลี่ย (Mean) จุดศูนย์กลาง, ค่าความแปรปรวนร่วม (Covariance) รูปร่าง และ น้ำหนัก (Weight) สัดส่วนของกลุ่มนั้น
จุดเด่นคือการจัดกลุ่มแบบ นุ่มนวล (Soft Clustering) ข้อมูลแต่ละจุดได้รับ คะแนนความน่าจะเป็น (Probability Score) บอกแนวโน้มการเป็นสมาชิกแต่ละกลุ่ม ทำให้เข้าใจความสัมพันธ์ข้อมูลละเอียดขึ้น
เบื้องหลังการทำงาน: EM Algorithm
การหาพารามิเตอร์ GMMs ใช้ EM Algorithm (Expectation-Maximization Algorithm) ซึ่งมีสองขั้นตอนหลัก
ขั้นตอนแรก: Expectation (E-step) โมเดลใช้พารามิเตอร์กลุ่มเกาส์เซียนเพื่อคำนวณ “ความรับผิดชอบ” (Responsibility) ของแต่ละกลุ่มต่อข้อมูล
ขั้นตอนที่สอง: Maximization (M-step) เมื่อได้ค่าความรับผิดชอบ ขั้นตอนนี้จะ ปรับปรุง (Update) พารามิเตอร์กลุ่มเกาส์เซียนทั้งหมด (ค่าเฉลี่ย, ค่าความแปรปรวนร่วม, น้ำหนัก) ให้ดีขึ้น เพื่ออธิบายชุดข้อมูลได้ดีที่สุด
กระบวนการ E-step และ M-step วนซ้ำจนกว่าพารามิเตอร์จะคงที่ หรือ ค่าล็อกความน่าจะเป็นสูงสุด (Log-Likelihood) เข้าสู่จุดคงที่ บ่งชี้ว่าโมเดลเรียนรู้การจัดกลุ่มที่ดีที่สุดแล้ว
GMMs เหนือกว่า K-Means อย่างไร?
GMMs มีข้อได้เปรียบสำคัญในการจัดการความซับซ้อนของข้อมูลที่ K-Means ทำได้ยาก
การจัดกลุ่มแบบนุ่มนวล (Soft Clustering) ให้ข้อมูลเชิงลึกมากกว่า
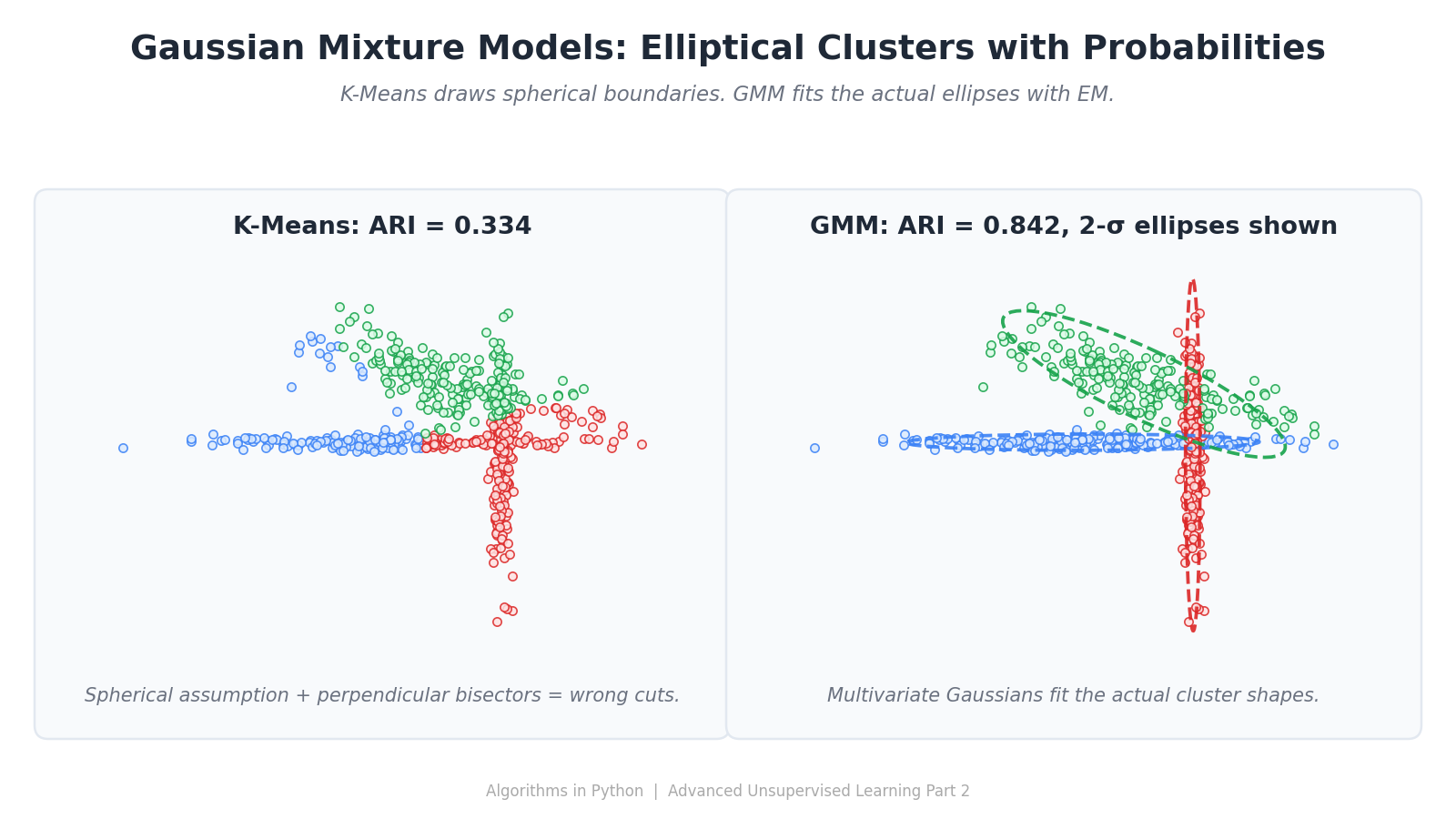
GMMs จัดการกับ รูปร่างของกลุ่มข้อมูลที่ไม่ใช่ทรงกลม (Non-Spherical Clusters) ได้ดี ด้วยค่าความแปรปรวนร่วม ทำให้แต่ละกลุ่มเป็นทรงรีหรือเอียงได้ สะท้อนความเป็นจริงของข้อมูลดีกว่า K-Means
ยังให้ ข้อมูลเชิงความน่าจะเป็น (Probabilistic Insights) GMMs ไม่เพียงบอกว่าข้อมูลอยู่กลุ่มไหน แต่ยังบอกความเชื่อมั่นในการเป็นสมาชิกของกลุ่มนั้นด้วย
ข้อควรพิจารณาเมื่อใช้งาน GMMs
แม้มีข้อดี GMMs ก็มีจุดที่ต้องพิจารณา
GMMs มีความซับซ้อนทาง การคำนวณ (Computational Cost) มากกว่า K-Means โดยเฉพาะเมื่อข้อมูลมีมิติสูงหรือจำนวนกลุ่มมาก
อีกประเด็นคือ ความไวต่อการเริ่มต้น (Initialization Sensitivity) หากเริ่มต้นไม่ดี EM Algorithm อาจติดใน จุดเหมาะสมที่สุดในท้องถิ่น (Local Optima)
สุดท้าย การกำหนด จำนวนกลุ่ม (Number of Components) หรือ K ที่เหมาะสมก็สำคัญ ใช้เกณฑ์อย่าง BIC (Bayesian Information Criterion) หรือ AIC (Akaike Information Criterion) ช่วยตัดสินใจได้
GMMs เปิดมิติใหม่ของการวิเคราะห์ข้อมูลเชิงลึกเหนือกว่าการจัดกลุ่มพื้นฐาน ช่วยให้เข้าใจโครงสร้างข้อมูลที่ซับซ้อนได้อย่างละเอียดอ่อนและยืดหยุ่น เหมาะสำหรับงานที่ต้องการความแม่นยำสูง.