K-Means Clustering: ปลดล็อกพลังของการจัดกลุ่มข้อมูลอัตโนมัติ
K-Means Clustering เป็นหนึ่งในเทคนิคที่ทรงพลังและได้รับความนิยมอย่างมากในโลกของ การเรียนรู้ของเครื่อง หรือ Machine Learning โดยเฉพาะอย่างยิ่งในกลุ่ม การเรียนรู้แบบไม่มีผู้สอน (Unsupervised Learning) แนวคิดหลักคือการจัดกลุ่มข้อมูลที่มีลักษณะคล้ายกันให้อยู่รวมกันเป็นหมวดหมู่หรือ คลัสเตอร์ (Cluster) โดยไม่ต้องมีข้อมูลกำกับ (Label) ไว้ล่วงหน้า เครื่องมือนี้ช่วยให้ค้นพบรูปแบบที่ซ่อนอยู่ในชุดข้อมูลขนาดใหญ่ได้อย่างมีประสิทธิภาพ
เมื่อพูดถึงการจัดกลุ่มข้อมูล สิ่งที่ K-Means ทำคือพยายามทำให้จุดข้อมูลภายในคลัสเตอร์เดียวกันมีความคล้ายคลึงกันมากที่สุดเท่าที่จะเป็นไปได้ ในขณะเดียวกันก็พยายามทำให้คลัสเตอร์ต่าง ๆ มีความแตกต่างกันมากที่สุด จำนวนคลัสเตอร์ที่ต้องการจัดกลุ่มจะถูกกำหนดด้วยตัวแปร “K” ซึ่งเป็นที่มาของชื่อ K-Means นั่นเอง
K-Means ทำงานอย่างไร: เจาะลึกกระบวนการ
เบื้องหลังการทำงานของ K-Means นั้นมีขั้นตอนที่ชัดเจนและซ้ำ ๆ กัน จนกว่าจะได้ผลลัพธ์ที่เหมาะสมที่สุด ลองมาดูกันทีละขั้นตอน
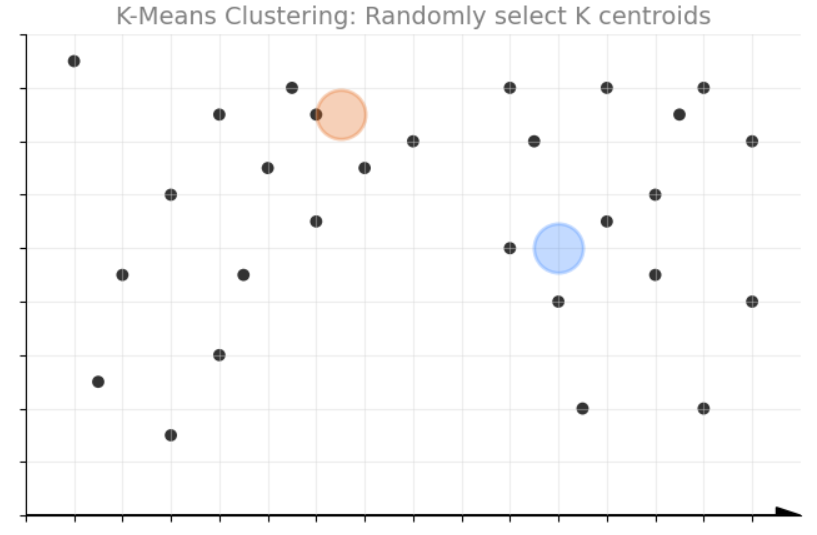
อย่างแรกคือ การกำหนดค่าเริ่มต้น (Initialization) ซึ่ง K-Means จะสุ่มเลือกจุดข้อมูลจำนวน K จุดขึ้นมาเป็นจุดศูนย์กลางของคลัสเตอร์ หรือที่เรียกว่า เซนทรอยด์ (Centroid) ในแต่ละคลัสเตอร์ การเลือกจุดเริ่มต้นนี้อาจส่งผลต่อผลลัพธ์สุดท้ายได้ ดังนั้นบางครั้งจึงมีการเลือกเซนทรอยด์เริ่มต้นหลายครั้งแล้วเลือกผลลัพธ์ที่ดีที่สุด
จากนั้นเข้าสู่ขั้นตอน การกำหนดจุดข้อมูล (Assignment Step) ในขั้นตอนนี้ จุดข้อมูลแต่ละจุดในชุดข้อมูลจะถูก “ส่งไป” ยังเซนทรอยด์ที่อยู่ใกล้ที่สุด โดยทั่วไปจะใช้ระยะทางแบบยูคลิด (Euclidean Distance) เป็นเกณฑ์ในการวัดความใกล้ชิด ทุกจุดข้อมูลจะถูกจัดสรรให้กับคลัสเตอร์ที่มีเซนทรอยด์ใกล้ที่สุด
เมื่อทุกจุดข้อมูลถูกกำหนดให้กับคลัสเตอร์เรียบร้อยแล้ว ก็จะถึงขั้นตอน การปรับปรุงเซนทรอยด์ (Update Step) โดยการคำนวณตำแหน่งใหม่ของเซนทรอยด์แต่ละคลัสเตอร์ ซึ่งทำได้โดยการหาค่าเฉลี่ยของพิกัดของจุดข้อมูลทั้งหมดที่อยู่ในคลัสเตอร์นั้น ๆ เซนทรอยด์จะ “เคลื่อนที่” ไปยังจุดศูนย์กลางที่แท้จริงของกลุ่มข้อมูลที่ถูกจัดสรรให้
สองขั้นตอนสุดท้ายนี้ คือการกำหนดจุดข้อมูลและการปรับปรุงเซนทรอยด์ จะถูกทำซ้ำไปเรื่อย ๆ กระบวนการจะหยุดลงเมื่อตำแหน่งของเซนทรอยด์ไม่มีการเปลี่ยนแปลงอย่างมีนัยสำคัญอีกต่อไป หรือเมื่อจำนวนรอบที่กำหนดไว้ล่วงหน้าสิ้นสุดลง ณ จุดนั้น ถือว่าคลัสเตอร์ถูกจัดตั้งขึ้นอย่างมีเสถียรภาพแล้ว
การเลือก K ที่เหมาะสมและข้อควรพิจารณา
การกำหนดค่า K หรือจำนวนคลัสเตอร์ที่เหมาะสมเป็นสิ่งสำคัญ หลายครั้งเราไม่มีความรู้ล่วงหน้าว่าข้อมูลควรถูกแบ่งออกเป็นกี่กลุ่ม วิธีที่นิยมใช้คือ วิธี Elbow Method โดยการพล็อตกราฟแสดงความสัมพันธ์ระหว่างจำนวนคลัสเตอร์ (K) กับค่าความผิดพลาดภายในคลัสเตอร์ (WCSS – Within-Cluster Sum of Squares) จุดที่กราฟมีการหักศอกคล้ายข้อศอก มักจะเป็นค่า K ที่เหมาะสมที่สุด
ข้อดีของ K-Means คือเป็นอัลกอริทึมที่เข้าใจง่าย ทำงานได้รวดเร็ว และมีประสิทธิภาพสูงสำหรับชุดข้อมูลขนาดใหญ่ แต่ก็มีข้อจำกัด เช่น อาจไวต่อการเลือกเซนทรอยด์เริ่มต้นที่สุ่มมา และมักจะทำงานได้ดีกับคลัสเตอร์ที่มีรูปร่างเป็นทรงกลมเท่านั้น นอกจากนี้ยังไวต่อข้อมูลผิดปกติ (Outliers) ซึ่งอาจส่งผลให้เซนทรอยด์เคลื่อนที่ไปจากตำแหน่งที่ควรจะเป็นได้
การประยุกต์ใช้ K-Means ในโลกจริง
K-Means ถูกนำไปใช้ในงานหลากหลายรูปแบบ ตัวอย่างที่เห็นได้ชัดคือ การแบ่งกลุ่มลูกค้า (Customer Segmentation) สำหรับธุรกิจ เพื่อทำความเข้าใจพฤติกรรมลูกค้าที่แตกต่างกัน และนำไปสู่การสร้างกลยุทธ์ทางการตลาดที่ตรงเป้าหมาย
นอกจากนี้ยังใช้ในการ จัดหมวดหมู่เอกสาร (Document Classification) การจัดกลุ่มรูปภาพ (Image Segmentation) หรือแม้กระทั่งการตรวจจับความผิดปกติ (Anomaly Detection) ในข้อมูลธุรกรรมทางการเงิน เพื่อระบุการทำธุรกรรมที่น่าสงสัยได้อย่างรวดเร็ว
K-Means เป็นเครื่องมือที่ยอดเยี่ยมในการสำรวจและทำความเข้าใจโครงสร้างของข้อมูลโดยไม่ต้องมีข้อมูลกำกับ มันช่วยให้ค้นพบข้อมูลเชิงลึกที่มีค่า และเป็นรากฐานสำคัญสำหรับการวิเคราะห์ข้อมูลในยุคปัจจุบัน