เบื้องหลังความแม่นยำ: AI จัดอันดับผลลัพธ์การค้นหาได้อย่างไร
เคยสงสัยไหมว่าทำไมเวลาค้นหาอะไรสักอย่าง ผลลัพธ์ที่ขึ้นมาถึงได้ตรงใจและเป็นประโยชน์กับเราขนาดนี้? เบื้องหลังความมหัศจรรย์นี้ ไม่ได้เกิดจากเวทมนตร์ แต่มาจากเทคโนโลยีสุดล้ำที่เรียกว่า Learning to Rank (L2R) ซึ่งเป็นการนำเอาปัญญาประดิษฐ์ หรือ AI มาช่วยให้การจัดอันดับข้อมูลในการค้นหามีประสิทธิภาพมากยิ่งขึ้น
จากเดิมที่ระบบค้นหาอาศัยเพียงแค่การจับคู่คำสำคัญอย่างตรงไปตรงมา วันนี้ AI ได้เข้ามาเปลี่ยนเกม ทำให้การค้นหาไม่ใช่แค่การหา “เจอ” แต่เป็นการหา “สิ่งที่ใช่ที่สุด”
การจัดอันดับการค้นหาแบบดั้งเดิม: ข้อจำกัดที่เห็นได้ชัด
ในอดีต ระบบการจัดอันดับผลการค้นหามักใช้หลักการที่ค่อนข้างเรียบง่าย
เช่น TF-IDF (Term Frequency-Inverse Document Frequency) ซึ่งจะให้คะแนนเอกสารตามความถี่ของคำที่ค้นหาในเอกสารนั้น ๆ เทียบกับเอกสารอื่น ๆ ในระบบ
วิธีนี้ใช้งานได้ดีในระดับหนึ่ง แต่มันมีข้อจำกัดอย่างมาก
เพราะมันไม่ได้เข้าใจถึง บริบท ความซับซ้อนของภาษา หรือความตั้งใจที่แท้จริงของผู้ใช้งาน
ผลลัพธ์ที่ได้อาจจะไม่ค่อยตรงใจ และไม่สามารถเรียนรู้จากพฤติกรรมการใช้งานที่เปลี่ยนแปลงไปได้เลย
ปฏิวัติการค้นหาด้วย Learning to Rank (L2R)
นี่คือจุดที่ Learning to Rank (L2R) เข้ามามีบทบาทสำคัญ
L2R คือชุดของเทคนิคแมชชีนเลิร์นนิงที่มุ่งเน้นการแก้ปัญหาการจัดอันดับผลลัพธ์
โดยเปลี่ยนจากการใช้กฎเกณฑ์ตายตัว มาเป็นการให้โมเดล AI เรียนรู้ ว่าควรจะจัดอันดับเอกสารอย่างไรจึงจะดีที่สุด
แนวคิดหลักคือการเปลี่ยนปัญหาการจัดอันดับให้เป็นปัญหาการเรียนรู้ภายใต้การกำกับดูแล
คือการให้ข้อมูลคู่ของคำค้นหาและเอกสาร พร้อมกับ คะแนนความเกี่ยวข้อง ที่มนุษย์กำหนดไว้เป็นตัวอย่างให้ AI เรียนรู้
หัวใจของ L2R: ฟีเจอร์และการเรียนรู้
การที่ AI จะจัดอันดับได้ดีนั้น จำเป็นต้องมี ข้อมูลคุณสมบัติ (features) ที่หลากหลายและครบถ้วน
ฟีเจอร์เหล่านี้ไม่ใช่แค่คำในเอกสาร แต่ยังรวมถึงปัจจัยอื่น ๆ อีกมากมาย
เช่น อายุของเอกสาร, จำนวนคลิกของผู้ใช้, ความนิยมของหน้าเว็บ, ลิงก์ที่เชื่อมโยง, และแม้แต่ประวัติการค้นหาของผู้ใช้งานแต่ละคน
โมเดล L2R จะใช้ข้อมูลคุณสมบัติเหล่านี้ร่วมกับชุดข้อมูลที่มีการให้คะแนนความเกี่ยวข้อง (labeled data)
เพื่อเรียนรู้รูปแบบและน้ำหนักของฟีเจอร์ต่าง ๆ ว่าฟีเจอร์ใดบ้างที่ส่งผลต่อการตัดสินใจว่าเอกสารใดควรจะอยู่สูงขึ้นในการจัดอันดับ
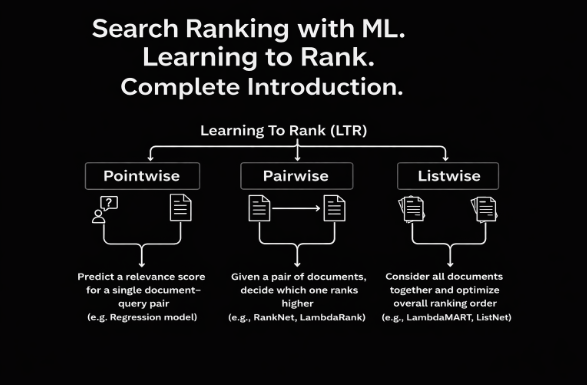
3 แนวคิดหลักใน Learning to Rank
L2R แบ่งออกเป็นสามแนวทางหลัก ๆ ซึ่งมีความซับซ้อนและประสิทธิภาพที่แตกต่างกัน:
-
Pointwise (แบบจุดต่อจุด): วิธีนี้จะพิจารณาเอกสารแต่ละฉบับอย่างอิสระ
โดยให้คะแนนความเกี่ยวข้องกับคำค้นหาหนึ่ง ๆ โดยไม่สนใจความสัมพันธ์ระหว่างเอกสารอื่น ๆ ที่อยู่ในรายการเดียวกัน
เหมือนกับการพิจารณาว่าเอกสารนี้ “ดีหรือไม่ดี” โดยลำพัง
ใช้ได้กับโมเดลการจัดหมวดหมู่ (classification) หรือการถดถอย (regression)
-
Pairwise (แบบคู่): วิธีนี้จะก้าวหน้าไปอีกขั้น ด้วยการเรียนรู้ที่จะเปรียบเทียบเอกสารเป็นคู่ ๆ
เพื่อตัดสินว่าเอกสารไหนควรจะถูกจัดอันดับให้สูงกว่าอีกเอกสารหนึ่ง
แนวทางนี้เริ่มพิจารณาถึงลำดับสัมพัทธ์ ซึ่งมักให้ผลลัพธ์ที่ดีกว่าแบบ Pointwise
ตัวอย่างโมเดลที่ใช้เช่น RankNet
-
Listwise (แบบรายการ): นี่คือแนวทางที่ซับซ้อนที่สุด และมีประสิทธิภาพสูงสุด
เพราะจะพิจารณาชุดเอกสารทั้งหมดที่เกี่ยวข้องกับคำค้นหาหนึ่ง ๆ พร้อมกัน
และพยายามปรับปรุงลำดับของทั้งรายการโดยตรง เพื่อให้ได้รายการที่เหมาะสมที่สุด
แนวทางนี้ใกล้เคียงกับปัญหาการจัดอันดับในโลกจริงมากที่สุด
โดยมีเป้าหมายคือการเพิ่มคุณภาพของ ทั้งรายการผลลัพธ์ ไม่ใช่แค่เอกสารเดี่ยว ๆ หรือคู่ ๆ
การใช้ Learning to Rank ทำให้ระบบการค้นหาสามารถมอบผลลัพธ์ที่แม่นยำ เป็นส่วนตัว และปรับตัวได้ตามพฤติกรรมของผู้ใช้ที่เปลี่ยนแปลงไปได้อย่างต่อเนื่อง ไม่ว่าจะเป็นการค้นหาในเว็บ, อีคอมเมิร์ซ, หรือแม้แต่การแนะนำเนื้อหาต่าง ๆ เราได้ประโยชน์จากความฉลาดของ AI ที่ทำงานอยู่เบื้องหลัง ทำให้การเข้าถึงข้อมูลเป็นเรื่องง่ายและมีประสิทธิภาพอย่างที่ไม่เคยเป็นมาก่อน