ปลดล็อกความเร็ว API: กลยุทธ์ Sharding เพื่อระบบที่ลื่นไหล
ระบบที่เติบโตขึ้นมักมาพร้อมความท้าทาย บางครั้ง API ของเราอาจเริ่มตอบสนองช้าลง ทั้งที่ไม่ได้มีข้อผิดพลาดร้ายแรงอะไรเลย
ปัญหาอาจไม่ได้อยู่ที่โค้ดรันช้า แต่เป็นการแย่งกันเข้าถึงข้อมูลสำคัญบางอย่างต่างหาก โดยเฉพาะเมื่อมีผู้ใช้งานพร้อมกันมหาศาล
นี่คือสถานการณ์ที่นักพัฒนาหลายคนต้องเผชิญเมื่อแอปพลิเคชันขยายตัว
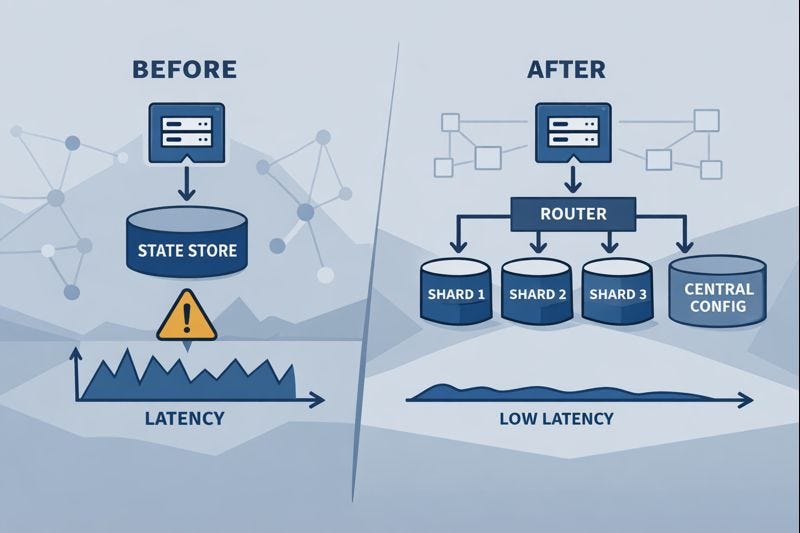
“สถานะ” ที่กลายเป็นคอขวด
ในแอปพลิเคชันที่ต้องจัดการข้อมูลจำนวนมาก บ่อยครั้งเราเก็บข้อมูลสำคัญเหล่านี้ไว้ในหน่วยความจำชั่วคราว หรือที่เรียกว่า “สถานะ” (State) เพื่อให้เข้าถึงได้รวดเร็ว เช่น แคชข้อมูลผู้ใช้ หรือการตั้งค่าสำคัญต่างๆ
ปัญหาจะเกิดขึ้นเมื่อคำขอจากผู้ใช้จำนวนมากพยายามเข้าถึงหรือแก้ไข “สถานะ” ก้อนเดียวกันนี้พร้อมๆ กัน
ลองจินตนาการถึงตู้เก็บเอกสารสำคัญที่มีกุญแจดอกเดียว ใครจะหยิบเอกสารก็ต้องรอคิวกัน ทำให้การทำงานล่าช้าไปหมด การล็อคข้อมูลทั้งหมดเพื่อป้องกันความเสียหาย แม้จะจำเป็น แต่กลับทำให้เกิด คอขวด (Bottleneck) ที่ร้ายแรง
ทุกคำขอต้องรอคิว ส่งผลให้ API ตอบสนองช้าลงอย่างมาก
แม้จะเพิ่มเครื่องเซิร์ฟเวอร์ (Horizontal Scaling) หรือเพิ่มทรัพยากรให้เซิร์ฟเวอร์เดียว (Vertical Scaling) ก็อาจไม่ช่วยแก้ปัญหานี้ได้โดยตรง
เพราะปัญหาที่แท้จริงคือการแย่งกันเข้าถึงข้อมูล ภายใน แต่ละอินสแตนซ์ของแอปพลิเคชันนั่นเอง
Sharding: แบ่งเพื่อความคล่องตัว
แนวคิดในการแก้ปัญหานี้คือ การแบ่งส่วนข้อมูล หรือ Sharding แทนที่จะมี “สถานะ” ก้อนใหญ่ก้อนเดียว เราจะแบ่งมันออกเป็นส่วนเล็กๆ หลายๆ ส่วน แต่ละส่วนจะดูแลตัวเอง และมีกลไกการล็อคเป็นของตัวเองแยกต่างหาก
เปรียบเสมือนการแบ่งตู้เก็บเอกสารออกเป็นหลายๆ ตู้เล็กๆ แต่ละตู้มีกุญแจของตัวเอง
เมื่อระบบต้องการเข้าถึงข้อมูล ระบบจะรู้ได้ทันทีว่าข้อมูลนั้นอยู่ส่วนแบ่งไหน แล้วไปเปิดกุญแจเฉพาะตู้เอกสารนั้นโดยตรง
สิ่งที่เกิดขึ้นคือ แทนที่จะต้องล็อคข้อมูลทั้งหมด ตอนนี้เราเพียงแค่ล็อคส่วนเล็กๆ ที่กำลังถูกใช้งานเท่านั้น
ส่วนข้อมูลอื่นๆ ยังคงเปิดให้เข้าถึงได้พร้อมกัน ทำให้เกิด การทำงานพร้อมกัน (Concurrency) ที่สูงขึ้นมาก ส่งผลให้ประสิทธิภาพโดยรวมของระบบดีขึ้นอย่างก้าวกระโดด
ขั้นตอนการนำ Sharding ไปใช้
การนำ Sharding มาปรับใช้มีหลักการสำคัญที่เข้าใจง่าย:
1. กำหนดจำนวนส่วนแบ่ง (Shards)
โดยทั่วไปแล้ว จะเลือกจำนวนที่เป็นเลขยกกำลังของ 2 (เช่น 256 หรือ 512) เพื่อให้การคำนวณมีประสิทธิภาพ
และมักจะสัมพันธ์กับจำนวนคอร์ของ CPU ที่เซิร์ฟเวอร์นั้นมี เพื่อการกระจายโหลดที่ดีที่สุด
2. กลไกการระบุส่วนแบ่ง (Hashing)
เราต้องการวิธี “ชี้ทาง” ว่าข้อมูลแต่ละชิ้นควรจะไปอยู่ส่วนแบ่งไหน โดยใช้ ฟังก์ชันแฮช (Hash Function) ที่รวดเร็วและกระจายข้อมูลได้ดี
ระบบจะนำคีย์ของข้อมูลไปเข้าฟังก์ชันแฮช เพื่อคำนวณออกมาเป็นตัวเลข จากนั้นนำตัวเลขนั้นมาหารเอาเศษกับจำนวนส่วนแบ่ง เพื่อให้ได้ดัชนีของส่วนแบ่งที่ถูกต้อง
3. การจัดการการเข้าถึงในแต่ละส่วนแบ่ง
แต่ละส่วนแบ่งควรมีกลไกป้องกันการเข้าถึงพร้อมกัน ตัวเลือกที่ดีคือการใช้ Read-Write Mutex (RWMutex) ซึ่งอนุญาตให้ผู้อ่านหลายคนเข้าถึงข้อมูลพร้อมกันได้ แต่จะอนุญาตให้ผู้เขียนคนเดียวเท่านั้นที่เข้าถึงได้ในแต่ละครั้ง
สิ่งนี้ช่วยเพิ่มประสิทธิภาพการอ่านข้อมูลให้สูงขึ้นโดยไม่กระทบความถูกต้องของข้อมูล
ผลลัพธ์อันทรงพลัง
เมื่อนำเทคนิค Sharding มาปรับใช้กับระบบที่เคยมีปัญหาคอขวดจาก “สถานะ” ที่ใช้ร่วมกัน จะเห็นผลลัพธ์ที่ชัดเจนทันที:
- API ตอบสนองเร็วขึ้น: เวลาหน่วง (Latency) ลดลงอย่างมาก ทำให้ผู้ใช้ได้รับประสบการณ์ที่ดีขึ้น
- รองรับผู้ใช้งานมากขึ้น: ระบบสามารถจัดการคำขอพร้อมกันได้จำนวนมหาศาลอย่างมีเสถียรภาพ
- ประสิทธิภาพโดยรวมดีขึ้น: ทำให้แอปพลิเคชันทำงานได้ราบรื่นแม้ภายใต้โหลดสูงสุด
การแบ่งส่วนข้อมูลแบบ Sharding จึงเป็นกลยุทธ์ที่ทรงพลังในการเพิ่มขีดความสามารถของแอปพลิเคชันที่ต้องการความเร็วและการประมวลผลพร้อมกันจำนวนมาก โดยไม่ต้องพึ่งพาระบบฐานข้อมูลภายนอกที่ซับซ้อน หรือการปรับโครงสร้างระบบขนาดใหญ่เสมอไป
นี่คือหนึ่งในวิธีที่ช่วยให้ระบบสามารถเติบโตได้อย่างไร้กังวล