สุดยอดเทคโนโลยีแบ่งแยกวัตถุแบบละเอียด: รู้จัก Mask R-CNN
ในโลกของคอมพิวเตอร์วิทัศน์ เราก้าวข้ามจากการแค่ระบุได้ว่า “มีวัตถุอะไรอยู่ในภาพบ้าง” ไปสู่การทำความเข้าใจภาพที่ลึกซึ้งยิ่งขึ้น
ความต้องการของเราไม่ใช่เพียงแค่รู้ว่ามีรถยนต์ แต่ยังอยากรู้ว่ารถยนต์คันไหนเป็นคันไหน และมันอยู่ตรงไหนของภาพอย่างแม่นยำในระดับพิกเซล
เทคโนโลยีอย่าง Mask R-CNN นี่แหละ ที่เข้ามาตอบโจทย์ความท้าทายนี้ได้อย่างยอดเยี่ยม
จากแค่ “เห็น” สู่ “เข้าใจอย่างลึกซึ้ง” ในโลกของคอมพิวเตอร์วิทัศน์
ลองนึกภาพว่าคุณต้องการให้คอมพิวเตอร์สามารถ “มองเห็น” และ “เข้าใจ” โลกเหมือนมนุษย์
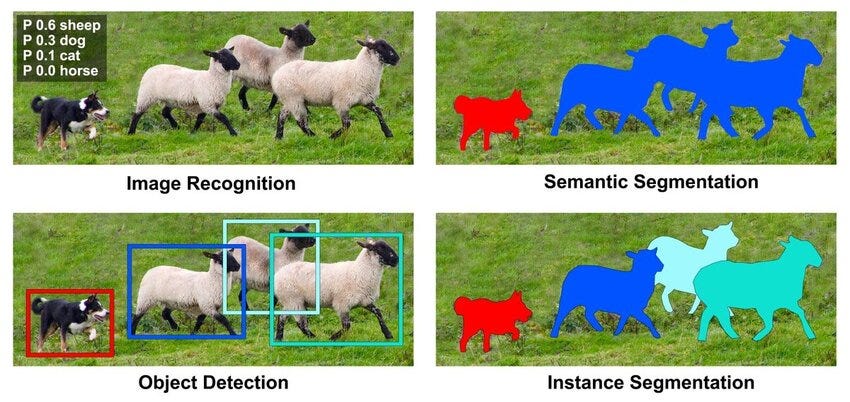
ในระยะแรก คอมพิวเตอร์เรียนรู้ที่จะบอกว่า “นี่คือแมว” หรือ “นี่คือหมา” ซึ่งเรียกว่า การจำแนกภาพ (Image Classification)
จากนั้นก็พัฒนาไปสู่การบอกตำแหน่งของวัตถุด้วย กล่องขอบเขต (Bounding Box) ซึ่งก็คือ Object Detection ที่ระบุได้ว่า “มีรถอยู่ตรงนี้”
แต่ในบางสถานการณ์ การรู้เพียงแค่กล่องสี่เหลี่ยมอาจยังไม่พอ เราต้องการความละเอียดที่มากกว่านั้น
การจำแนกภาพสามระดับ: แตกต่างกันอย่างไร
เพื่อเห็นภาพชัดเจน เรามาดูการจำแนกภาพสามระดับกัน
เริ่มจาก Semantic Segmentation เทคนิคนี้จะแบ่งแยกพิกเซลทุกพิกเซลในภาพออกเป็นหมวดหมู่ต่างๆ เช่น พิกเซลทั้งหมดที่เป็น “ถนน” หรือ “ท้องฟ้า” มันยอดเยี่ยมในการทำความเข้าใจบริบท แต่ไม่ได้แยกว่า “รถคันที่หนึ่ง” กับ “รถคันที่สอง” ต่างกันอย่างไร
นี่คือจุดที่ Instance Segmentation เข้ามามีบทบาทสำคัญ เทคนิคนี้ไม่เพียงแต่ระบุประเภทของวัตถุและตำแหน่งในระดับพิกเซลเท่านั้น แต่ยังสามารถแยกแยะวัตถุแต่ละชิ้นออกจากกันได้ แม้จะเป็นวัตถุประเภทเดียวกันก็ตาม
ยกตัวอย่างเช่น หากมีรถยนต์สองคันจอดเรียงกัน Instance Segmentation จะสร้าง “หน้ากาก” (mask) ที่แม่นยำสำหรับรถยนต์แต่ละคัน แยกเป็นรถคันที่ 1 และรถคันที่ 2 อย่างชัดเจนในระดับพิกเซล
ทำความรู้จัก Mask R-CNN: หัวใจสำคัญของ Instance Segmentation
Mask R-CNN คือสถาปัตยกรรมโครงข่ายประสาทเทียมที่ทรงพลังและเป็นที่ยอมรับอย่างกว้างขวางสำหรับการทำ Instance Segmentation
มันถูกพัฒนาต่อยอดมาจาก Faster R-CNN ซึ่งเป็นโมเดลสำหรับ Object Detection และได้เพิ่มความสามารถในการสร้าง หน้ากากพิกเซล ที่แม่นยำสำหรับวัตถุแต่ละชิ้นเข้ามา
การทำงานของ Mask R-CNN ทำให้คอมพิวเตอร์ไม่เพียงแต่รู้ว่า “มีอะไร” และ “อยู่ตรงไหน” แต่ยังรู้ว่า “วัตถุแต่ละชิ้นมีรูปร่างอย่างไร” ด้วยความละเอียดระดับพิกเซล
กลไกเบื้องหลัง Mask R-CNN ทำงานอย่างไร
Mask R-CNN มีส่วนประกอบหลักๆ ที่ทำงานร่วมกันอย่างชาญฉลาด:
เริ่มต้นด้วย Backbone Network เช่น ResNet หรือ FPN ที่ทำหน้าที่ดึงคุณสมบัติสำคัญจากภาพต้นฉบับออกมา
จากนั้น Region Proposal Network (RPN) จะสแกนภาพและเสนอ “พื้นที่ที่น่าจะเป็นวัตถุ” ขึ้นมาหลายๆ จุด
สิ่งสำคัญที่ทำให้ Mask R-CNN แม่นยำคือ RoIAlign ซึ่งเป็นกลไกที่ช่วยจัดแนวข้อมูลคุณสมบัติจากพื้นที่ที่ถูกเสนอ ให้สอดคล้องกับขนาดที่แน่นอนของวัตถุ โดยปราศจากข้อผิดพลาดที่เกิดจากการปัดเศษข้อมูล ซึ่งแตกต่างจาก RoIPooling ที่อาจลดทอนความแม่นยำของตำแหน่งพิกเซล
สุดท้าย Mask R-CNN จะมีส่วนหัวสองส่วนที่ทำงานแบบขนานกัน
ส่วนหนึ่งจะทำหน้าที่ จำแนกประเภทวัตถุ และ ปรับแต่งตำแหน่งของกล่องขอบเขต ให้แม่นยำยิ่งขึ้น
อีกส่วนหนึ่งซึ่งเป็นเอกลักษณ์ของ Mask R-CNN จะทำหน้าที่ สร้างหน้ากากไบนารี ในระดับพิกเซลสำหรับวัตถุแต่ละชิ้นที่ตรวจพบออกมา นี่คือหัวใจสำคัญที่ทำให้ได้ผลลัพธ์การแบ่งแยกวัตถุที่ละเอียดลออ
การประยุกต์ใช้ Mask R-CNN ในโลกจริง
ความสามารถในการแบ่งแยกวัตถุแต่ละชิ้นอย่างแม่นยำของ Mask R-CNN เปิดประตูสู่การใช้งานที่หลากหลายและน่าทึ่ง
ใน รถยนต์ไร้คนขับ มันช่วยให้รถสามารถแยกแยะคนเดินเท้า รถคันอื่น หรือป้ายจราจรแต่ละชิ้นออกจากกันได้อย่างชัดเจน ทำให้การตัดสินใจปลอดภัยยิ่งขึ้น
ใน การแพทย์ สามารถช่วยนักรังสีวิทยาในการวิเคราะห์ภาพทางการแพทย์ เพื่อระบุและแยกแยะเซลล์มะเร็ง เนื้อร้าย หรืออวัยวะต่างๆ ได้อย่างแม่นยำ
นอกจากนี้ยังนำไปใช้ใน หุ่นยนต์ เพื่อให้หุ่นยนต์สามารถหยิบจับวัตถุได้อย่างถูกต้อง หรือใน ระบบรักษาความปลอดภัย สำหรับการติดตามบุคคลหรือวัตถุที่สนใจในฝูงชน
เทคโนโลยีนี้กำลังผลักดันขีดจำกัดของปัญญาประดิษฐ์ ทำให้เครื่องจักรสามารถ “มองเห็น” และ “เข้าใจ” โลกในแบบที่เราไม่เคยจินตนาการมาก่อน มันเป็นเครื่องมือสำคัญที่ช่วยให้การประยุกต์ใช้ AI ก้าวหน้าไปอีกขั้น สร้างประโยชน์มหาศาลให้กับอุตสาหกรรมและชีวิตประจำวันของเรา